Tribe: On Homecoming and Belonging by Sebastian Junger
Tribe is an interesting, relatively quick read about the phenomena of loneliness in modern society, a place where people, more or less, lack a tribe. Junger makes strong arguments about why we may feel better in tribal cultures, with more loyalty, sense of belonging, and meaning. He explains why many veterans, even if they have not seen the fields of battle, have increasing rates of PTSD after returning to civilian life.
This book was recommended to me after moving home to Minnesota and feeling like I had no community, no structure, that I didn’t really have anything that mattered all that much. While reading Tribe I found myself nodding my head along with the words and finding that a lot of what Junger had to say made a lot of sense to me and that I really related to it. It made me realize that a lot of what I felt, the sever loneliness and longing for something more, was likely due to the loss of community, and coming together to work towards a common goal, that I had at my former startup.
Favorite Quotes
“The sheer predictability of life in an American suburb left me hoping – somewhat irresponsibly – for a hurricane or a tornado or something that would require us to all band together to survive. Something that would make us a tribe.”
“This book is about why that sentiment is such a rare and precious thing in modern society, and how the lack of it has affected us all. It’s about what we can learn from tribal societies about loyalty and belonging and the eternal human quest for meaning. It’s about why – for many people – war feels better than peace and hardship can turn out to be a great blessing and disasters are somethings remembered more fondly than weddings or tropical vacations. Humans don’t mind hardship, in fact they thrive on it; what they mind is not feeling necessary. Modern society has perfected the art of making people not feel necessary.”
“It may say something about human nature that a surprising number of Americans – mostly men – wound up joining Indian society rather than staying in their own. They emulated Indians, married them, were adopted by them, and on some occasions even fought alongside them. And the opposite almost never happened: Indians almost never ran away to join white society. Emigration always seemed to go from the civilized to the tribal.”
“On the other hand, Franklin continued, white captives who were liberated from the Indians were almost impossible to keep at home: ‘Tho ransomed by their friends, and treated with all imaginable tenderness to prevail with them to stay among the English, yet in a short time they become disgusted with our manner of life… and take the first good opportunity of escaping again into the woods.'”
“For all the temptations of native life, one of the most compelling might have been its fundamental egalitarianism. Personal property was usually limited to whatever could be transported by horse or on foot, so gross inequalities of wealth were difficult to accumulate… Social status came through hunting and war, which all men had access to, and women had far more autonomy and sexual freedom – and bore fewer children – than women in white society. ‘Here I have no master,’ an anonymous colonial woman was quoted by the secretary of the French legation as saying about her life with the Indians. “I am the equal of all the women in the tribe, I do what I please without anyone’s saying anything about it, I work only for myself, I shall marry if I wish and be unmarried again when I wish. Is there a single woman as independent as I in your cities?”
“But as societies become more affluent they tend to require more, rather than less, time and commitment by the individual, and it’s impossible that many people feel that affluence and safety simply aren’t a good trade for freedom.”
“One study in the 1960s found that nomadic !Kung people of the Kalahari Desert needed to work as little as twelve hours a week to survive – roughly one-quarter the hours of the average urban executive at the time… The relatively relaxed pace of !Kung life – even during times of adversity – challenged long -standing ideas that modern society created a surplus of leisure time. It created exactly the opposite: a desperate cycle of work, financial obligation, and more work… Among anthropologists, the !Kung are thought to present a fairly accurate picture of how our hominid ancestors lived for more than a million years before the advent of agriculture… Early humans would most likely have lived in nomadic bands of around fifty people, much like the !Kung… And they would have done almost everything in the company of others. They would have almost never been alone.”
“…And as society modernized, people found themselves able to live independently from any communal group. A person living in a modern city or suburb can, for the first time in history, go through an entire day – or an entire life- mostly encountering complete strangers. They can be surrounded by others and yet feel deeply, dangerously alone… The evidence that this is hard on us is overwhelming. Although happiness is notoriously subjective and difficult to measure, mental illness is not. Numerous cross-cultural studies have shown that modern society- despite its nearly miraculous advances in medicine, science, and technology – is afflicted with some of the highest rates of depression, schizophrenia, poor health, anxiety, and chronic loneliness in human history. As affluence and urbanization rise in a society, rates of depression and suicide tend to go up rather than down. Rather than buffering people from clinical depression, increased wealth in a society seems to foster it.”
“…there is remarkably little evidence of depression-based suicide in tribal societies. Among the American Indians, for example, suicide was understood to apply in very narrow circumstances: in old age to avoid burdening the tribe, in a ritual paroxysms of grief following the death of a spouse, in a hopeless but heroic battle with an enemy, and in an attempt to avoid the agony of torture. “
“In the United States, white middle-aged men currently have the highest (suicide) rate at nearly 30 suicides per 100,000.”
“In 2015, the George Washington Law Review surveyed more than 6,000 lawyers and found that conventional success in the legal profession – such as high billable hours or making partner at a law firm – had zero correlation with levels of happiness and well-being reported by the lawyers themselves… The findings are in keeping with something called self-determination theory, which holds that human beings need three basic things in order to be content: they need to feel competent at what they do, they need to feel authentic in their lives, and they need to feel connected to others. These values are considered intrinsic to human happiness and far outweigh extrinsic values such as beauty, money, and status. Bluntly put, modern society seems to emphasize extrinsic values over intrinsic ones, and as a result, mental health issues refuse to decline with growing wealth.”
“The economic and marketing forces of modern society have engineered an environment that maximizes consumption at the long-term cost of well-being. In effect, humans have dragged a body with a long hominid history into an overfed, malnourished, sedentary, sunlight-deficient, sleep-deprived, competitive, inequitable, and socially-isolating environment with dire consequences.”
“…Clearly, touch and closeness are vital to the health of baby primates – including humans… Only in Northern European societies do children go through the well-known development stage of bonding with stuffed animals; elsewhere, children get their sense of safety from the adults sleeping near them.”
“Before the war, projections for psychiatric breakdown in England ran as high as four million people, but as the Blitz progressed, psychiatric hospitals around the country saw admissions go down. Emergency services in London reported an average of only two cases of bomb neuroses a week. Psychiatrists watched in puzzlement as long-standing patients saw their symptoms subside during the period of intense air raids. Voluntary admissions to psychiatric wards noticeably declined, and even epileptics reported having fewer seizures. ‘Chronic neurotics of peacetime now drive ambulances,’ one doctor remarked. Another ventured to suggest that some people actually did better during wartime.”
“The positive effects of war on mental health were first noticed by the great sociologist Emile Durkheim, who found that when European countries went to ware, suicide rates dropped. Psychiatric wards in Paris were strangely empty during both world wars, and that remained true even as the German army rolled into the city in 1940.”
“An Irish psychologist named H. A. Lyons found that suicide rates in Belfast dropped 50 percent during the riots of 1969 and 1970, and homicide and other violent crimes also went down. Depression rates for both men and women declined abruptly during that period, with men experiencing the most extreme drop in the most violent districts.”
“‘When people are actively engaged in a cause, their lives have more purpose… with a resulting improvement in mental health’, Lyons wrote in the Journal of Psychosomatic Research in 1979. ‘It would be irresponsible to suggest violence as a means of improving mental health, but the Belfast findings suggest that people will feel better psychologically if they have more involvement with their community.'”
“Fritz’s theory was that modern society has gravely disrupted the social bonds that have always characterized the human experience, and that disasters thrust people back into a more ancient, organic way of relating. Disasters, he proposed, create a community of sufferers that allows individuals to experience an immensely reassuring connection to others. As people come together to face an existential threat, Fritz found that class differences are temporarily erased, income disparities become irrelevant, race is overlooked, and individuals are assessed simply by what they are willing to do for the group.”
“The beauty and tragedy of the modern world is that it eliminates many situations that require people to demonstrate a commitment to the collective good. Protected by police and fire departments and relieved of most of the challenges of survival, an urban man might go through his entire life without having to come to the aid of someone in danger – or even give up his dinner.”
“What catastrophes seem to do – sometimes in the span of a few minutes – is turn back the clock on ten thousand years of social evolution. Self-interest gets subsumed into group interest because there is no survival outside group survival, and that creates a social bond that many people sorely miss.”
“For a former solider to miss the clarity and importance of his wartime duty is one thing, but for civilians to is quite another, ‘Whatever I say about ware, I still hate it’, one survivor made sure to tell me after I’d interviewed her about the nostalgia of her generation. ‘I do miss something from the war. But I also believe that the world we are living in – and the peace we have – is very fucked up if somebody is missing war. And many people do… Although she was safe in Italy, and finally healing form her wounds, the loneliness she felt was unbearable. She was worried that if the war never stopped, everyone would be killed and she would be left alone in the world.”
“‘I missed being that close to people, I missed being loved in that way’, she told me. ‘In Bosnia – as it is now – we don’t trust each other anymore; we became really bad people. We didn’t learn the lesson of the war, which is how important it is to share everything you have with human beings close to you. The best way to explain it is that the war makes you an animal. We were animals. It’s insane – but that’s the basic human instinct, to help another human being who is sitting or standing or lying close to you… We were the happiest then, and we laughed more.'”
“But in addition to all the destruction and loss of life, war also inspires ancient human virtues of courage, loyalty, and selflessness that can be utterly intoxicating to the people who experience them… The Iroquois Nation presumably understood the transformative power of war when they developed parallel systems of government that protected civilians from warriors and vice versa. Peacetime leaders, called sachems, were often chosen by women and had complete authority over the civil affairs of the tribe until war broke out. At that point war leaders took over, and their sole concern was the physical survival of the tribe… If the enemy tried to negotiate an end to hostilities, however, it was the sachems, not the war leaders, who made the final decision. If the offer was accepted, the war leaders stepped down so that the sachems could resume leadership of the tribe… The Iroquois system reflected the radically divergent priorities that a society must have during peacetime and during war. Because modern society often fights wars far away from the civilian population, soldiers wind up being the only people who have to switch back and forth.”
“Treating combat veterans is different from treating rape victims (PTSD), because rape victims don’t have this idea that some aspects of their experience are worth retaining.”
“Combat veterans are, statistically, no more likely to kill themselves than veterans who were never under fire. The much-discusses estimate of twenty-two vets a day committing suicide in the United States is deceptive: it was only in 2008 that – for the first time in decades – the suicide rate among veterans surpassed the civilian rate in America, and though each death is enormously tragic, the majority of those veterans were over the age of fifty… The discrepancy might be due to the fact that intensive training and danger create what is known as unit cohesion – strong emotional bonds within the company or the platoon – and high unit cohesion is correlated with lower rates of psychiatric breakdown.”
“35 years after finally acknowledging the problem, the US military now has the highest reported PTSD rate in its history – and probably in the world. American soldiers appear to suffer PTSD at around twice the rate of British soldiers who were in combat with them… Since only 10 percent of our armed forces experience actual combat, the majority of vets claiming to suffer from PTSD seem to have been affected by something other than direct exposure to danger. This is not a new phenomenon: decade after decade and war after war, American combat deaths have generally dropped while disability claims have risen… Soldiers in Vietnam suffered one-quarter the mortality rate of troops in WWII, for example, but filed for both physical and psychological disability compensation at a rate that was 50 percent higher… Today’s vets claim three times the number of disabilities that Vietnam vets did, despite a generally warm reception back home and a casualty rate, thank God, that is roughly one-third what it was in Vietnam.”
“The vast majority of traumatized vets are not faking their symptoms, however. They return from wars that are safer than those their fathers and grandfathers fought, and yet far greater numbers of them wind up alienated and depressed. This is true even for people who didn’t experience combat. In other words, the problem doesn’t seem to be trauma on the battlefield so much as reentry into society. And vets are not alone in this. It’s common knowledge in the Peace Corps that as stressful as life in a developing country can be, returning to a modern country can be far harder. One study found that one in four Peace Corps volunteers reported experiencing significant depression after their return home, and that figure more than doubled for people who had been evacuated from their host country during wartime or some other kind of emergency… It makes one wonder exactly what it is about modern society that is so mortally dispiriting to come home to.”
“What people miss (after re-entering civilian life) presumably isn’t danger or loss, but the unity that these things often engender. There are obvious stresses on a person in a group, but there may be even greater stresses on a person in isolation, so during disasters there is a net gain in well-being. Most primates, including humans, are intensely social, and there are very few instances of lone primates surviving in the wild. A modern soldier returning from combat – or a survivor of Sarajevo – goes form the kind of close-knit group that humans evolved for, back into a society where most people work outside the home, children are educated by strangers, families are isolated from wider communities, and personal gain almost completely eclipses collective good.”
“Our fundamental desire, as human beings, is to be close to others, and our society does not allow for that… In humans, lack of social support has been found to be twice as reliable at predicting PTSD as the severity of the trauma itself.”
“Israel is arguably the only modern country that retains a sufficient sense of community to mitigate the effects of combat on a mass scale… Those who come back from combat are reintegrated into a society where those experiences are very well understood. We did a study of seventeen-year-olds who had lost their father in the military, compared to those who had lost their fathers to accidents. The ones whose fathers died in combat did much better than those whose fathers hadn’t… The Israelis are benefiting from what the author and ethicist Austin Dacey describes as a ‘shared public meaning’ of the war. Shared public meaning gives soldiers a context for their losses and their sacrifice that is acknowledged by most of the society. That helps keep at bay the sense of futility and rage that can develop among soldiers during a war that doesn’t seem to end.”
“Such public meaning is probably not generated by the kinds of formulaic phrases, such as ‘thank you for your service’ that many Americans now feel compelled to offer soldiers and vets. Neither is it generated by honoring vets at sporting events, allowing them to board planes first, or giving them minor discounts at stores. If anything, these token acts only deepen the chasm between the military and civilian populations by highlighting the fact that some people serve their country, but the vast majority don’t.”
“Anthropologists like Kohrt, Hoffman and Abramowitz have identified three factors that seem to crucially affect a combatant’s transition back into civilian life. First, cohesive and egalitarian tribal societies do a very good job at mitigating the effects of trauma, but by their very nature, many modern societies are exactly the opposite: hierarchical and alienating… Secondly, ex-combatants shouldn’t be seen as victims… Third, and perhaps most important, veterans need to feel that they’re just as necessary and productive back in society as they were on the battlefield. Iroquois warriors who dominated just about every tribe within 500 miles of their home territory would return to a community that still needed them to hunt and fish and participate in the fabric of everyday life. There was no transition when they came home because – much like life in Israel – the battlefield was an extension of society, and vice versa.”
“There are many costs to modern society, starting with its toll on the global ecosystem and working one’s way down to its toll on the human psyche, but the most dangerous loss may be to community.”
“The earliest and most basic definition of community – of tribe – would be the group of people that yo would both help feed and help defend. A society that doesn’t offer its members the chance to act selflessly in these ways isn’t a society in any tribal sense of the word; it’s just a political entity that, lacking enemies, will probably fall apart on its own. Soldiers experience this tribal way of thinking at war, but when they come home they realize that the tribe they were actually fighting for wasn’t their country, it was their unit. It makes absolutely no sense to make sacrifices for a group that, itself, isn’t willing to make sacrifices for you. That is the position American soldiers have been in for the past decade and a half.”
“The public is often accused of being disconnected from its military, but frankly it’s disconnected from just about everything… This fundamental lack of connectedness allows people to act in trivial but incredibly selfish ways. Rachel Yehuda pointed to littering as the perfect example of an everyday symbol of disunity in society. ‘It’s a horrible thing to see because it sort of encapsulates this idea that you’re in it alone, that there isn’t a shared ethos of trying to protect something shared. It’s the embodiment of every man for himself. It’s the opposite of the military.’ When you throw trash on the ground, you apparently don’t see yourself as truly belonging to the world that you’re walking around in.”
“Gang shootings – as indiscriminate as they often are – still don’t have the nihilistic intent of rampages. Rather, they are rooted in an exceedingly strong sense of group loyalty and revenge, and bystanders sometimes get killed in the process.”
“Rampage killings dropped significantly during WWII, then rose again in the 1980s and have been rising ever since. It may be worth considering whether middle-class American life – for all its material good fortune – has lost some essential sense of unity that might otherwise discourage alienated men from turning apocalyptically violent.”
“New York’s suicide rate dropped around 20 percent in the six months following the attacks (on 9/11), the murder rate dropped by 40 percent, and pharmacists saw no increase in the number of first-time patients filling prescriptions for anti-anxiety and antidepressant medication. Furthermore, veterans who were being treated for PTSD at the VA experienced a significant drop in their symptoms in the months after the September 11th attack.”
“Today’s veterans often come home to find that, although they’re willing to die for their country, they’re not sure how to live for it. It’s hard to know how to live for a country that regularly tears itself apart along every possible ethnic and demographic boundary… To make matters worse, politicians occasionally (editors note: very often these days) accuse rivals of deliberately trying to harm their own country – a charge so destructive to group unity that most past societies would probably have punished it as a form of treason. It’s complete madness, and the veterans know this. In combat, soldiers all but ignore differences of race, religion, and politics within their platoon. It’s no wonder many of them get so depressed when they come home.”
“I know what coming back to America from a war zone is like because I’ve done it so many times. First there is a kind of shock at the level of comfort and affluence that we enjoy, but that is followed by the dismal realization that we live in a society that is basically at war with itself. People speak with incredible contempt about – depending on their views – the rich, the poor, the educated, the foreign-born, the president, or the entire US government. It’s a level of contempt that is usually reserved for enemies in wartime, except that now it’s applied to our fellow citizens. Unlike criticism, contempt is particularly toxic because it assumes a moral superiority in the speaker. Contempt is often directed at people who have been excluded from a group or declared unworthy of its benefits. Contempt is often used by governments to provide rhetorical cover for torture or abuse. Contempt is one of four behaviors that, statistically, can predict divorce in married couples. People who speak with contempt for one another will probably not remain united for long.”
“The most alarming rhetoric comes out of the dispute between liberals and conservatives, and it’s a dangerous waste of time because they’re both right. The perennial conservative concern about high taxes supporting a nonworking ‘underclass’ has entirely legitimate roots in our evolutionary past and shouldn’t be dismissed out of hand. Early hominids lived a precarious existence where freeloaders were a direct threat to survival, and so they developed an exceedingly acute sense of of whether they were being taken advantage of by members of their own group. But by the same token, one of the hallmarks of early human society was the emergence of a culture of compassion that cared for the ill, the elderly, the wounded, and the unlucky. In today’s terms, that is a common liberal concern that also has to be taken into account. Those two driving forces have coexisted for hundreds of thousands of years in human society and have been duly codified in this country as a two-party political system. The eternal argument over so-called entitlement programs- and, more broadly, over liberal and conservative thought- will never be resolved because each side represents an ancient and absolutely essential component of our evolutionary past.”
“If you want to make a society work, then you don’t keep underscoring the places where you’re different – you underscore your shared humanity.”
“The United States is so powerful that the only country capable of destroying her might be the United States herself, which means that the ultimate terrorist strategy would be to just leave the country alone. That way, America’s ugliest partisan tendencies could emerge unimpeded by the unifying effects of war. The ultimate betrayal of tribe isn’t acting competitively – that should be encouraged- but predicating your power on the excommunication of others from the group. That is exactly what politicians of both parties try to do when they spew venomous rhetoric about their rivals.” (*cough* Trump *cough*)
“In 2009, an American soldier named Bowe Bergdahl slipped through a gap in the concertina wire at his combat outpost in southern Afghanistan and walked off into the night. He was quickly captured by a Taliban patrol, and his absence triggered a massive search by the US military that put thousands of his fellow soldiers at risk. The level of betrayal felt by soldiers was so extreme that many called for Bergdahl to be tried for treason when he was repatriated five years later… The collective outrage at Sergeant Bergdahl was based on very limited knowledge but provides a perfect example of the kind of tribal ethos that every group – or country- deploys in order to remain unified and committed to itself… Bergdahl put a huge number of people at risk and may have caused the deaths of up to six soldiers. But in purely objective terms, he caused his country far less harm than the financial collapse of 2008, when bankers gambled trillions of dollars of taxpayer money on blatantly fraudulent mortgages… Almost 9 million people lost their jobs during the financial crisis, 5 million families lost their homes, and the unemployment rate doubled to around 10 percent… For nearly a century, the national suicide rate has almost exactly mirrored the unemployment rate, and after the financial collapse, America’s suicide rate increased by nearly 5 percent. In an article published in 2012 in The Lancet, epidemiologists who study suicid estimated that the recession cost almost 5,000 additional American lives during the first two years – disproportionately among middle-aged white men. That is close to the nation’s losses in the Iraq and Afghan wars combined. If Sergeant Bergdahl betrayed his country – and that’s not a hard case to make – surely the bankers and traders who caused the financial collapse did as well. And yet they didn’t provoke nearly the kind of outcry that Bergdahl did.”



















 is simply a tuning parameter used to weigh which part of our minimization problem we want to place more importance on. Is it more important for us to minimize the energy of the controlled output, z? Then select
is simply a tuning parameter used to weigh which part of our minimization problem we want to place more importance on. Is it more important for us to minimize the energy of the controlled output, z? Then select 
 and
and  are symmetric positive-definite matrices.
are symmetric positive-definite matrices.





 and
and  matrices? And second, how the hell do we actually solve that algebraic Riccati equation?
matrices? And second, how the hell do we actually solve that algebraic Riccati equation? . From here we just vary the single parameter
. From here we just vary the single parameter  until we get something that has a decent response.
until we get something that has a decent response.



![\begin{aligned} 2) \displaystyle \qquad \hat{x}_0^+ &= E(x_0)\\ P_0^+ &= E \left[ \left(x_0 - \hat{x}_0^+ \right ) \left(x_0 - \hat{x}_0^+ \right)^T \right ] \\ \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D++2%29+%5Cdisplaystyle+%5Cqquad+%5Chat%7Bx%7D_0%5E%2B+%26%3D+E%28x_0%29%5C%5C++P_0%5E%2B+%26%3D+E+%5Cleft%5B+%5Cleft%28x_0+-+%5Chat%7Bx%7D_0%5E%2B+%5Cright+%29+%5Cleft%28x_0+-+%5Chat%7Bx%7D_0%5E%2B+%5Cright%29%5ET+%5Cright+%5D+%5C%5C++%5Cend%7Baligned%7D++&bg=ffffff&fg=000&s=1&c=20201002)



![\begin{aligned} 6) \displaystyle \qquad K_k &= P_k^- H_k^T \left( H_k P_k^- H_k^T + M_k R_k M_k^T \right ) ^{-1}\\ \hat{x}_k^+ &= \hat{x}_k^- + K-k \left [y_k - h_k(\hat{x}_k^-, 0) \right ]\\ P_k^+ &= \left (I - K_k H_k \right ) P_k^- \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D++6%29+%5Cdisplaystyle+%5Cqquad+K_k+%26%3D+P_k%5E-+H_k%5ET+%5Cleft%28+H_k+P_k%5E-+H_k%5ET+%2B+M_k+R_k+M_k%5ET+%5Cright+%29+%5E%7B-1%7D%5C%5C++%5Chat%7Bx%7D_k%5E%2B+%26%3D+%5Chat%7Bx%7D_k%5E-+%2B+K-k+%5Cleft+%5By_k+-+h_k%28%5Chat%7Bx%7D_k%5E-%2C+0%29+%5Cright+%5D%5C%5C++P_k%5E%2B+%26%3D+%5Cleft+%28I+-+K_k+H_k+%5Cright+%29+P_k%5E-++%5Cend%7Baligned%7D++&bg=ffffff&fg=000&s=1&c=20201002)
 , where k is the dimension of the measurement vector, and n is the dimension of the state vector.[2]
, where k is the dimension of the measurement vector, and n is the dimension of the state vector.[2] filter, which is actually less complicated because it’s been studied since the days of Newton (it involves a two state Newtonian dynamical system with a position measurement). We have fading memory Kalman filters for when we have a crap system model and we don’t want our estimate to diverge from the true state, The
filter, which is actually less complicated because it’s been studied since the days of Newton (it involves a two state Newtonian dynamical system with a position measurement). We have fading memory Kalman filters for when we have a crap system model and we don’t want our estimate to diverge from the true state, The  filter for when we need a very robust filter to minimize the worst-case estimation error, the hybrid extended Kalman filter, for when we want to combine continuous and discrete time dynamics, the second order extended Kalman filter where we employ a second order Taylor series expansion of our state transition and measurement matrices to reduce the linearization error of the standard EKF, the iterated extended Kalman filter where we perform our linearization process again (or as many times as we like) after getting our a posteriori state estimate. If we want to get even trickier there’s the unscented Kalman filter that aims to further reduce linearization errors present in the EKF by transforming our probability density functions through a nonlinear function (which is difficult) by means of deterministic vectors known as sigma points whose ensemble mean and covariance are equal to our state mean and estimation-error covariance. Finally, we have the very common particle filter that just brute forces its way through estimation, which is pretty awesome now that computation power is relatively cheap.
filter for when we need a very robust filter to minimize the worst-case estimation error, the hybrid extended Kalman filter, for when we want to combine continuous and discrete time dynamics, the second order extended Kalman filter where we employ a second order Taylor series expansion of our state transition and measurement matrices to reduce the linearization error of the standard EKF, the iterated extended Kalman filter where we perform our linearization process again (or as many times as we like) after getting our a posteriori state estimate. If we want to get even trickier there’s the unscented Kalman filter that aims to further reduce linearization errors present in the EKF by transforming our probability density functions through a nonlinear function (which is difficult) by means of deterministic vectors known as sigma points whose ensemble mean and covariance are equal to our state mean and estimation-error covariance. Finally, we have the very common particle filter that just brute forces its way through estimation, which is pretty awesome now that computation power is relatively cheap.

![\begin{aligned} 2) \displaystyle \qquad \hat{x}_0^+ &= E(X_0)\\ P_0^+ &= E \left [ (x_0 - \hat{x}_0^+)(x_0 - x_0^+) \right ] \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D++2%29+%5Cdisplaystyle+%5Cqquad+%5Chat%7Bx%7D_0%5E%2B+%26%3D+E%28X_0%29%5C%5C++P_0%5E%2B+%26%3D+E+%5Cleft+%5B+%28x_0+-+%5Chat%7Bx%7D_0%5E%2B%29%28x_0+-+x_0%5E%2B%29+%5Cright+%5D++%5Cend%7Baligned%7D++&bg=ffffff&fg=000&s=1&c=20201002)
 refers to the initial a posteriori state estimate, and
refers to the initial a posteriori state estimate, and  refers to the initial a posteriori covariance.
refers to the initial a posteriori covariance.![\begin{aligned} 3) \displaystyle \qquad P_k^- &= F_{k-1}P_{k-1}^+ F_{k-1}^T + Q_{k-1}\\ K_K &= P_k^- H_k^T \left (H_k P_k^- H_k^T + R_k \right ) ^{-1} \\ &= P_k^+ H_K^T R_k^{-1} \\ \hat{x}_k^- &= F_{k-1} \hat{x}_{k-1}^+ + G_{k-1} u_{k-1} \\ \hat{x}_k^+ &= \hat{x}_k^- + K_k \left( y_k - H_k \hat{x}_k^- \right ) \\ P_k^+ &= \left (I - K_kH_k \right ) P_k^- \left (I- K_k H_k \right )^T + K_k R_k K_k^T \\ &= \left [ (P_k^-)^{-1} + H_k^T R_k^{-1} H_k \right ] ^{-1}\\ &= \left (I - K_k H_k \right )P_K^- \\ \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D++3%29+%5Cdisplaystyle+%5Cqquad+P_k%5E-+%26%3D+F_%7Bk-1%7DP_%7Bk-1%7D%5E%2B+F_%7Bk-1%7D%5ET+%2B+Q_%7Bk-1%7D%5C%5C++K_K+%26%3D+P_k%5E-+H_k%5ET+%5Cleft+%28H_k+P_k%5E-+H_k%5ET+%2B+R_k+%5Cright+%29+%5E%7B-1%7D+%5C%5C++%26%3D+P_k%5E%2B+H_K%5ET+R_k%5E%7B-1%7D+%5C%5C++%5Chat%7Bx%7D_k%5E-+%26%3D+F_%7Bk-1%7D+%5Chat%7Bx%7D_%7Bk-1%7D%5E%2B+%2B+G_%7Bk-1%7D+u_%7Bk-1%7D+%5C%5C++%5Chat%7Bx%7D_k%5E%2B+%26%3D+%5Chat%7Bx%7D_k%5E-+%2B+K_k+%5Cleft%28+y_k+-+H_k+%5Chat%7Bx%7D_k%5E-+%5Cright+%29+%5C%5C++P_k%5E%2B+%26%3D+%5Cleft+%28I+-+K_kH_k+%5Cright+%29+P_k%5E-+%5Cleft+%28I-+K_k+H_k+%5Cright+%29%5ET+%2B+K_k+R_k+K_k%5ET+%5C%5C++%26%3D+%5Cleft+%5B+%28P_k%5E-%29%5E%7B-1%7D+%2B+H_k%5ET+R_k%5E%7B-1%7D+H_k+%5Cright+%5D+%5E%7B-1%7D%5C%5C++%26%3D+%5Cleft+%28I+-+K_k+H_k+%5Cright+%29P_K%5E-+%5C%5C++%5Cend%7Baligned%7D++&bg=ffffff&fg=000&s=1&c=20201002)
 is the a priori state estimate, and
is the a priori state estimate, and  is the a posteriori state estimate. The first representation of the a posteriori covariance is known as the Joseph stabilized version, and is the most robust, whereas the third version is much more succinct, but is less robust. If the second expression for the Kalman gain is used, so too must the second expression for the a posteriori covariance.
is the a posteriori state estimate. The first representation of the a posteriori covariance is known as the Joseph stabilized version, and is the most robust, whereas the third version is much more succinct, but is less robust. If the second expression for the Kalman gain is used, so too must the second expression for the a posteriori covariance. is known as the innovations, which is simply the difference between the the actual measurement and the predicted measurement. This is the part of the measurement that contains new information about the state. As you can see, the Kalman filter then weights the innovations by the kalman gain, and then adds it to the a priori state estimate, to finally obtain the a posteriori state estimate. Therefore, the only difference between the a priori and a posteriori state estimate is that the latter takes the new measurement into account, whereas the former is the state estimate according to what our dynamic model predicts. If you’re coming at this from a mobile robotics application, people will generally refer the dynamic model as the motion model, and the state estimate the belief.
is known as the innovations, which is simply the difference between the the actual measurement and the predicted measurement. This is the part of the measurement that contains new information about the state. As you can see, the Kalman filter then weights the innovations by the kalman gain, and then adds it to the a priori state estimate, to finally obtain the a posteriori state estimate. Therefore, the only difference between the a priori and a posteriori state estimate is that the latter takes the new measurement into account, whereas the former is the state estimate according to what our dynamic model predicts. If you’re coming at this from a mobile robotics application, people will generally refer the dynamic model as the motion model, and the state estimate the belief.


 . known as the estimator gain matrix, or if you’re dealing with a Kalman filter it’s called the Kalman gain matrix, either way, it’s the same thing: just a weighting of how confident we are in our measurements based on their statistics.
. known as the estimator gain matrix, or if you’re dealing with a Kalman filter it’s called the Kalman gain matrix, either way, it’s the same thing: just a weighting of how confident we are in our measurements based on their statistics.
 based on the previous estimate,
based on the previous estimate,  and the measurement
and the measurement  .
.![\begin{aligned} 2) \displaystyle \qquad \hat{x}_0 &= E(x)\\ P_0 &= E \left [ (x - \hat{x}_0)(x - \hat{x}_0)^T \right ] \\ \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D++2%29+%5Cdisplaystyle+%5Cqquad+%5Chat%7Bx%7D_0+%26%3D+E%28x%29%5C%5C++P_0+%26%3D+E+%5Cleft+%5B+%28x+-+%5Chat%7Bx%7D_0%29%28x+-+%5Chat%7Bx%7D_0%29%5ET+%5Cright+%5D+%5C%5C++%5Cend%7Baligned%7D++&bg=ffffff&fg=000&s=1&c=20201002)
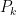 is the estimation-error covariance. There’s a bit of a trick we play next to get the ball rolling: if we don’t know anything about x before measurements start rolling in, we set
is the estimation-error covariance. There’s a bit of a trick we play next to get the ball rolling: if we don’t know anything about x before measurements start rolling in, we set  . If we know exactly what x is before measurements roll in we set
. If we know exactly what x is before measurements roll in we set  . So, basically the less we know about x the larger we set our estimation-error covariance.
. So, basically the less we know about x the larger we set our estimation-error covariance.
 is the covariance of our zero-mean noise process,
is the covariance of our zero-mean noise process, 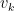 . In the real world this is literally just the variance in your measurement variable when your state is held constant. So, if our output measurement variable were, for example, the angular velocity of a table saw blade, we could run the table saw at constant velocity, collect our data, and determine R to be the variance in our angular velocity measurements.
. In the real world this is literally just the variance in your measurement variable when your state is held constant. So, if our output measurement variable were, for example, the angular velocity of a table saw blade, we could run the table saw at constant velocity, collect our data, and determine R to be the variance in our angular velocity measurements.

 is the initial position,
is the initial position,  is the initial velocity, and a is the acceleration. If we then measure r at many different times and fit a quadratic to the resulting position vs time curve, we will have an estimate of our initial velocity and acceleration.
is the initial velocity, and a is the acceleration. If we then measure r at many different times and fit a quadratic to the resulting position vs time curve, we will have an estimate of our initial velocity and acceleration.![\begin{aligned} 5) \displaystyle \qquad y_k &= x_1 + x_2 t_k + x_3 t_k^2 + v_k \\ E(v_k^2) &= R_k \\ H_k &= \left [ 1 \, t_k \, t_k^2 \right ] \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D++5%29+%5Cdisplaystyle+%5Cqquad+y_k+%26%3D+x_1+%2B+x_2+t_k+%2B+x_3+t_k%5E2+%2B+v_k+%5C%5C++E%28v_k%5E2%29+%26%3D+R_k+%5C%5C++H_k+%26%3D+%5Cleft+%5B+1+%5C%2C+t_k+%5C%2C+t_k%5E2+%5Cright+%5D++%5Cend%7Baligned%7D++&bg=ffffff&fg=000&s=1&c=20201002)


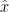 we arrive at
we arrive at








 is the left pseudo inverse. The pseudo inverse exists if
is the left pseudo inverse. The pseudo inverse exists if  and H is full rank. This just means that we need to have more measurements than there are number of variables and the measurements must be linearly independent.
and H is full rank. This just means that we need to have more measurements than there are number of variables and the measurements must be linearly independent.








 , or the output angle as
, or the output angle as
 , where k varies from 1 to N (the number of samples), and the sample period is
, where k varies from 1 to N (the number of samples), and the sample period is 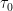 . For a discrete set of samples, a cumulative sum can be used to give N values of
. For a discrete set of samples, a cumulative sum can be used to give N values of  . In this case the cumulative sum of the gyro output samples at each
. In this case the cumulative sum of the gyro output samples at each  is taken and each sum obtained is then multiplied by the sample period
is taken and each sum obtained is then multiplied by the sample period  , where m is the averaging factor. The averaging factor can be chosen arbitrarily as some value according the inequality
, where m is the averaging factor. The averaging factor can be chosen arbitrarily as some value according the inequality  . [2]
. [2] 
 and < > is the ensemble average. Upon expanding the ensemble average in equation 5 we obtain the following estimate of the Allan variance:
and < > is the ensemble average. Upon expanding the ensemble average in equation 5 we obtain the following estimate of the Allan variance:
 by:
by:




 is the entire process variation (NOT JUST THE DRIVEN NOISE VARIATION),
is the entire process variation (NOT JUST THE DRIVEN NOISE VARIATION),  is the inverse of the correlation time,
is the inverse of the correlation time,  , and
, and  , and the entire time series variance will appear as the peak at time lag = 0. Note that the driven noise standard deviation cannot be validated via autocorrelation. Also note that matlab has two different autocorrelation functions that will produce slightly different results if your time scales are short (autocorr and xcorr), as well as an autocovariance function, xcov. Autocorr and xcov are normalized by the process mean such that a constant process will have a steady autocorrelation (autocorrelation is just autocovariance scaled by the inverse of the process variance). xcorr, however, does not do this, so a constant process will have a decaying autocorrelation as the time lag increases, which results in a shortening of the summation by 1 element each iteration.
, and the entire time series variance will appear as the peak at time lag = 0. Note that the driven noise standard deviation cannot be validated via autocorrelation. Also note that matlab has two different autocorrelation functions that will produce slightly different results if your time scales are short (autocorr and xcorr), as well as an autocovariance function, xcov. Autocorr and xcov are normalized by the process mean such that a constant process will have a steady autocorrelation (autocorrelation is just autocovariance scaled by the inverse of the process variance). xcorr, however, does not do this, so a constant process will have a decaying autocorrelation as the time lag increases, which results in a shortening of the summation by 1 element each iteration.
 is the Allan deviation maxima.
is the Allan deviation maxima.
 vs
vs  .
.![13) \displaystyle \qquad \sigma^2(\tau) = \frac{2B^2}{\pi}\left [ln 2 - \frac{sin^3(x)}{2x^2}\left (sin(x) + 4xcos(x)\right ) + Ci(2x) - Ci(4x) \right ]](https://s0.wp.com/latex.php?latex=13%29+%5Cdisplaystyle+%5Cqquad++%5Csigma%5E2%28%5Ctau%29+%3D+%5Cfrac%7B2B%5E2%7D%7B%5Cpi%7D%5Cleft+%5Bln+2+-+%5Cfrac%7Bsin%5E3%28x%29%7D%7B2x%5E2%7D%5Cleft+%28sin%28x%29+%2B+4xcos%28x%29%5Cright+%29+%2B+Ci%282x%29+-+Ci%284x%29+%5Cright+%5D&bg=ffffff&fg=000&s=1&c=20201002)
 ,
,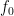 is the cutoff frequency, and
is the cutoff frequency, and
 .
.
 .
.
 .
.![17) \displaystyle \qquad \sigma^2(\tau) = \frac{(q_c T_c)^2}{\tau}\left [1- \frac{T_c}{2\tau}\left (3-4e^{-\frac{\tau}{T_c}}+e^{-\frac{2\tau}{T_c}}\right )\right ]](https://s0.wp.com/latex.php?latex=17%29+%5Cdisplaystyle+%5Cqquad+%5Csigma%5E2%28%5Ctau%29+%3D+%5Cfrac%7B%28q_c+T_c%29%5E2%7D%7B%5Ctau%7D%5Cleft+%5B1-+%5Cfrac%7BT_c%7D%7B2%5Ctau%7D%5Cleft+%283-4e%5E%7B-%5Cfrac%7B%5Ctau%7D%7BT_c%7D%7D%2Be%5E%7B-%5Cfrac%7B2%5Ctau%7D%7BT_c%7D%7D%5Cright+%29%5Cright+%5D&bg=ffffff&fg=000&s=1&c=20201002)
 we obtain:
we obtain:
 we obtain:
we obtain:
