Effective Python, following in the same vein as the other “Effective” programming books, has a list of best practices to follow for becoming proficient in this particular programming language. Brett Slatkin has provided 90 very thorough examples to help boost your Python 3.x skills ranging from the most basic of things like Item 1: Know Which Version of Python You’re Using, to more esoteric things like Item 51: Prefer Class Decorators Over Metaclasses for Composable Class Extensions.
Overall I found the book to be pretty solid and would recommend it to anyone that’s either incredibly late to the game in hopping to Python 3.x now that Python 2.7 has been a dead language for a year and a half, or to someone that’s taken an introductory Python course and has played with the language for a little while and wants to get better.
I have worked through all of the examples in the book and created iPython notebooks from them which can be found in my GitHub repository. I would encourage you to check out the notebooks to see if purchasing the book would be a good option for you (I think it would be).
Select Code Snippets
Item 4: Prefer Interpolated F-Strings Over C-Style Format Strings and str.format
pantry = [
('avocados', 1.25),
('bananas', 2.5),
('cherries', 15),
]
# comparing C-style, format and f-string formatting
for i, (item, count) in enumerate(pantry):
old_style = '#%d: %-10s = %d' % (i+1, item.title(), round(count))
new_style = '#{}: {:<10s} = {}'.format(i+1, item.title(), round(count))
f_string = f'#{i+1}: {item.title():<10s} = {round(count)}'
print(old_style)
print(new_style)
print(f_string)
Item 25: Enforce Clarity with Keyword-Only and Positional-Only Arguments
'''
We can require callers to be clear about their intentions by
using keyword-only arguments, which can be supplied by keyword only,
never by position. To do this, we use the * symbol in the
argument list to indicate the end of positional arguemtns and
the beginning of keyword-only arguments:
'''
def safe_division_c(number, divisor, *,
ignore_overflow=False,
ignore_zero_division=False):
try:
return number / divisor
except OverflowError:
if ignore_overflow:
return 0
else:
raise
except ZeroDivisionError:
if ignore_zero_division:
return float('inf')
else:
raise
result = safe_division_c(1.0, 0, ignore_zero_division=True)
print(result)
'''
trying to call the function requiring keyword-only arguments with
positional arguments will fail:
'''
#result = safe_division_c(1.0, 10**500, True, False)
'''
A problem still remains, though: Callers may specify the first
two required arguments (number and divisor) with a mix of
positions and keywords. If I later decide to change the
names of these first two arguments it will break all the
existing callers. This is especially problematic because I
never intended for number and divisor to be part of an explicit
interface for this function; they were just confnenient parameter
names that I chose for the implementation, and I didn't expect
anyone to rely on them explicitly.
Python 3.8 introduces a solution to this problem, called
positional-only arguments. These arguments can be supplied
only by position and never by keyword. The symbol/ in the
argument list indicates where positional-only arguments end:
'''
def safe_divisor_d(numerator, denominator, /, *,
ignore_overflow=False,
ignore_zero_division=False):
try:
return number / divisor
except OverflowError:
if ignore_overflow:
return 0
else:
raise
except ZeroDivisionError:
if ignore_zero_division:
return float('inf')
else:
raise
result = safe_division_d(1.0, 0, ignore_zero_division=True)
print(result)
result = safe_division_d(2, 5)
print(result)
'''
Now an exception is raised if keywords are used for the
positional-only arguments
'''
#safe_division_d(numerator=2, denominator=5)
Item 27: Use Comprehensions Instead of map and filter
# naive way (for loop and list.append)
a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
squares = []
for x in a:
squares.append(x**2)
print(squares)
# slightly better way (using map built-in function)
alt_squares = map(lambda x: x**2, a)
print(list(alt_squares))
# best way (list comprehensions)
alt_squares2 = [x**2 for x in a]
print(alt_squares2)
# Unlike map, list comprehensions let you easily filter items from the input list:
even_squares = [x**2 for x in a if x % 2 == 0]
print(even_squares)
# The filter built in function can be used along with map to achieve the same result, but is much harder to read:
alt = map(lambda x: x**2, filter(lambda x: x % 2 == 0, a))
print(list(alt))
Item 37: Compose Classes Instead of Nesting Many Levels of Built-in Types
from collections import namedtuple, defaultdict
# named tuple to represent a simple grade
Grade = namedtuple('Grade', ('score', 'weight'))
class Subject:
""" Class to represent a single subject that contains a set of grades."""
def __init__(self):
self._grades = []
def report_grade(self, score, weight):
self._grades.append(Grade(score, weight))
def average_grade(self):
total, total_weight = 0, 0
for grade in self._grades:
total += (grade.score * grade.weight)
total_weight += grade.weight
return total / total_weight
class Student:
""" Class to represent a set of subjects that are studied by a single student."""
def __init__(self):
self._subjects = defaultdict(Subject)
def get_subject(self, name):
return self._subjects[name]
def average_grade(self):
total, count = 0, 0
for subject in self._subjects.values():
total += subject.average_grade()
count += 1
return total / count
class GradeBook:
"""
Class to represent a container for all of the students,
keyed dynamically by their names.
"""
def __init__(self):
self._students = defaultdict(Student)
def get_student(self, name):
return self._students[name]
book = GradeBook()
albert = book.get_student('Albert Einstein')
math = albert.get_subject('Math')
math.report_grade(75, 0.05)
math.report_grade(65, 0.15)
math.report_grade(70, 0.80)
gym = albert.get_subject('Gym')
gym.report_grade(100, 0.40)
gym.report_grade(85, 0.60)
print(albert.average_grade())
Nine Practices to Extend the Life and Value of Your Software
Beyond Legacy Code was recommended to me by my good friend Paul a while back, and I really enjoyed this book for its brevity and high level summary of many best practices in software craftsmanship that get covered in more detail by books like CLEAN code, Refactoring, etc. I also enjoyed it due to his disdain for the scourge that is waterfall project management.
This is going to be a relative long post, as it is a thorough summary of the book and serves as a nice reference back to it (and writing all this stuff down helps me process and remember things better). I highly recommend this book as it serves as a nice high level summary of other software craftsmanship books and ties them all together. You’re not likely to see anything new in here unless you’re coming at it from a non-technical background, in which case I recommend this book even more, but I still found its strength to be its synthesizing nature.
Chapters 1 and 2
Bernstein himself describes the usage of the book with the paragraph: “How software is written may be an alien concept to most people, yet it affects us all. Because it has become such a complex activity, developers often find themselves trying to explain concepts for which their customers, and even their managers, may have no point of reference. This book helps bridge that communications gap and explains technical concepts in common sense language to help us forge a common understanding about what good software development actually is.“
What is Legacy Code?
Putting it quite succinctly, Bernstein states that legacy code is “most simply… code that, for a few different reasons, is particularly difficult to fix, enhance, and work with… You think of tangled, unintelligible structure, code that you have to change but don’t really understand. You think of sleepless nights trying to add in features that should be easy to add, and you think of demoralization, the sense that everyone on the team is so sick of a code base that it seems beyond care, the sort of code that you wish would die.” Michael Feathers further defines legacy code as any code without tests. “But having good unit tests presupposes that you have good, testable code, which is often not the case with legacy code, so you’ll have to clean up the code and put it into a better state.”
Why Waterfall Doesn’t Work
Bernstein likens the risks of using waterfall style project management to that of playing the odds in Las Vegas. “In order for anything to work, everything has to work. Programmers don’t see their code run with the rest of the system until integration – one of the last stages before release – when all the separate pieces of code are brought together to make a whole. When we put off integration until the very end, we’re basically playing roulette where we have to win ten times in a row in order to succeed.”
The author compares creating physical things, like a house, to that of virtual things, like software. If you’re building a house you will want to get everything you need to build it up front, but often with software we don’t have a good idea what that is. Case in point, if you were to try to build a house from scratch without ever having done it before, would you know what you needed to buy or do? That’s what software development usually is.
Bernstein states that “Batching things up doesn’t work well for things in the virtual space… It’s not just that it’s inefficient… It forces us to build things that are unchangeable.”
Anecdotes from early in the book
An outdated comment is worse than no comment at all. This turns the comment into a lie, and we don’t want lies in our code. Excessive comments are noise at best and worst they’re lies, however unintentional. Code should be self-expressive, and this is best accomplished by naming things well and using consistent metaphors to make software easy to follow and clear.
Most of what a software developer does lies in unexplored areas. Everyone knows it makes management – almost anyone in fact – feel comfortable if we rely on numbers, charts, and deadlines. But to do great things in any profession means to venture into the unknown, and the unknown can’t easily be quantified… Ultimately we measure because it gives us the feeling that we understand and are in control. But these are just illusions.”
The reason that we rarely know how long a particular task will take is that we’ve never done it before. It’s possible, and in fact probable, that we’ll miss a step… More than anything we need to think things through, and we can never do that as effectively as when we’re actually performing the task.
The tasks we perform when writing software are vastly different moment to moment, day to day, month to month, and project to project… The problems themselves, and their solutions, are often markedly dissimilar to ones we’ve encountered before.
Developing software is risky. It’s rarely done well and the software is practically obsolete moments after it’s written. Faced with this increased complexity, the traditional approach to fixing problems in software development is to create a better process. We rely on process to tell us what to do, to keep us on track, keep us honest, keep us on schedule, and so on. This is the basic philosophy behind waterfall development. Because changing code after the initial design phase is difficult to accomplish, we’ll prevent changes after the design is done. Since testing is time consuming and expensive, we’ll wait till the end of the project so we have to test only once. This approach makes sense in theory, but clearly is inefficient in practice.
Chapter 3: Smart People, New Ideas
Lean says waste in software development is any task that’s started but not yet complete: It’s work in progress. I would even go as far as to say that anything that isn’t software, or anything that doesn’t provide direct value to the customer, can be seen as waste.
The core of Agile is to, rather than create more process to assure quality, use less process so that developers have more time to focus on applying solid engineering practices.
Devs are almost never sure how long a project is going to take. Software design is, in many ways, barely past the starting line, and we’re not exactly sure we can finish a marathon. We can’t see the finish line from the starting line, and we’re not even sure in some sense how long the race actually is. The finish line might be any distance away, or we might know where it is but not how to get there.
Bernstein suggest that instead of concentrating on the whole race, we should concentrate on just one small piece along the way: this two weeks’ worth of development rather than the whole year. This way we can respond to individual portions of it and try to forecast things into the future.
He posits that one of the central things to do is to build in batches, which allows devs to take tasks from start to finish as quickly as possible, and smaller tasks can be taken to completion quicker.
Bernstein completes this chapter by quoting Jeff Sutherland, saying that the number one key success factor for Agile adoption is to demand technical excellence.
Chapter 4: The Nine Practices
If software is to be used it will need to be changed, so it must be written to be changeable. This is not how most software has been written. Most code is intertwined with itself so it’s not independently deployable or extendable, and that makes it expensive to maintain.
Bernstein states that the best software developers he knows are also the neatest. He assumed that fast coders had to be sloppy coders, but what he discovered was quite the opposite. The fastest programmers paid particular attention to keeping their code easy to work with. They don’t just declare instance variables at the top of their classes; they list them in alphabetical order (or however else it makes sense), they constantly rename methods and move them around until their right home is found, and they immediately delete dead code that’s not being used. These people weren’t faster in spite of keeping code quality high, they were faster because they kept their code quality high.
Principles: Principles point us in the right direction and take us closer to the true nature of what the principle applies to. They’re like lofty goals; things that we want to strive for because we know they’re good and virtuous.
Practices: A practice provides value at least most of the time, is easy to learn and easy to teach others, is so simple to do you can do it without actually thinking about it.
Principles guide practices; they tell us how to apply practices to maximal effect.
Anticipate or Accomodate
Without the right set of practices that support creating changeable code, we are unable to easily accommodate change with it happens and we pay a big price. This leaves us in a position where we have to anticipate change before it happens in order to accommodate it later. And that can be stressful. And stress never helps build a better product.
Anticipating future needs can be exhausting, and you’re probably going to be wrong most of the time anyway. Trying to anticipate all of your future needs can cause developers to waste time worrying about features and functionality that are not currently needed and robs them of valuable time to deal with the things that are needed right now. It’s better to just accept that things are going to change, and find ways to accommodate change once it’s asked for.
Given the costs involved in fixing bugs and adding features to existing software, Bernstein states that above and beyond all else, that good software does what it’s supposed to do and is changeable so it’s straightforward to address future needs. Making software changeable extends the return on investment of the initial effort to create it.
The purpose of the nine practices outlined in the book is therefore to help devs build bug-free software that is simpler (and therefore cheaper) to maintain and extend: build better / risk less.
The nine practices are:
Say What, Why and for Whom before How
Build in Small Batches
Integrate Continuously
Collaborate
Create CLEAN Code
Write the Test First
Specify Behaviors with Tests
Implement the Design Last
Refactor Legacy Code
Chapter 5: (Practice 1) Say What, Why and for Whom before How
As software developers, we want to know from the Product Owners and customers what they want and why they want it, and we want to know who it’s for – we don’t want them to tell us how to do it, because that’s our job.
Bernstein states that every great software development project he’s ever worked on has had a product owner. The PO is a superstar, but also the single wring-able neck. The final authority. The product owner is the relationship hub. Everyone goes to that person with updates and questions, and he or she filters that information. The PO is the person who says, “This is the next most important feature to build.”
The Product Owner orders the backlog and the features to be built, ensuring that the most important stuff gets built and the least important doesn’t.
Stories
A story is a one-sentence statement that describes:
what it is…
why it’s there…
and who it’s for.
Stories are a promise for a conversation. We don’t have enough information to build the feature, but we do have enough information to start a conversation about that feature. Stories are about making sure the focus remains on the development of the software itself, rather than on the plan for the development of the software. In agile we say “Barely sufficient documentation.”
A story is finite and speaks of a single feature for a specific type of user and for a single reason. When a story is finite it means it’s testable, and when a story is testable, you know when you’re done.
Set Clear Criteria for Acceptance Tests
Working from barely sufficient documentation, the team will need to know a few things before starting to build a feature. Rather than working from step-by-step requirements, product owners need to know
What are the criteria for acceptance?
How much detail do they need in order to engage in a conversation with developers?
Acceptance criteria state:
What it should do
When it’s working
When we’re ready to move on
Seven Strategies for Product Owners
Be the SME The PO must be the subject matter expert and have a deep understanding of what the product is to be. POs must spend time visualizing the system and working through examples before it’s built so they understand it as much as possible.
Use development for discovery While POs must hold the product vision, they must also keep an open mind to discovering better solutions in the process of building it. Iterative development provides many opportunities for feedback, and POs should take these opportunities to get features that are in the process of being built into the hands of users to make sure development is on track.
Help developers understand why and for whom Understanding why a feature is being requested and who it is for gives developers a better context for what’s being requested. Developers can often come up with better, more maintainable implementations that get the same job done but that are also more generalizable, flexible and extendable.
Describe what you want, not how to get it One of the many benefits of stories over specifications or use cases is the focus on what to build and not how to build it. POs must be careful not to tell developers how to do something, and instead focus on what they want done.
Answer questions quickly The PO must always be available to answer questions that come up throughout development. Often, answering developer questions becomes the bottleneck during development, and when the PO is not available, development slows down and developers must make assumptions that may turn out not to be true.
Remove dependencies POs typically don’t code, but they can help the team by working with other teams their developers depend on to ensure the dependencies don’t hold anyone up. They order the backlog and must ensure that any dependencies across teams have enough lead time.
Support refactoring It’s a POs job to request features, but a PO must also be sensitive to the quality of the code being produced so it remains maintainable and extendable. This often means supporting the team when they feel that refactoring can help.
Seven Strategies for Writing Better Stories
See it as a placeholder Stories alone are not meant to replace requirements. They are supposed to help start a conversation between the Product Owner and the developer. It is those conversations that replace requirements; stories are just placeholders. Use stories to capture the main ideas you want to bring to sprint planning for further discussion.
Focus on the “what” Stories focus on what a feature does, not how it does it. Developers should determine how to build a feature as they’re coding it but first figure out what the feature will do and how it will be used.
Personify the “who” Knowing who a feature is for helps developers better understand how the feature is likely to be used, which gives insight into improving the design. This may not be an actual person, but anything that is consuming that feature.
Know why a feature is wanted Understanding why a feature is wanted and what it’s trying to achieve can often lead us to better options. The “so that” clause of a story specifies why a feature is desirable by stating the benefits of the feature.
Start simple and add enhancements later Incremental design and development is not only the most efficient way to build software, it also offers the best results. Designs that are allowed to emerge are often more accurate, maintainable, and extendable.
Think about edge cases Stories state the happy path but there are often other paths we have to take, including alternate paths and exception/error handling. Bernstein typically jots down edge cases on the back of the story card to keep track of them, and then later write tests for them to drive their implementation.
Use acceptance criteria Before embarking on implementing a story it’s important to have clearly defined acceptance criteria. This is best expressed as a set of acceptance tests, either using an acceptance testing tool such as SpecFlow, FIT, or Cucumber, or you can just jot it down on the story card.
Chapter 6: (Practice 2) Build in Small Batches
If we need to tell ourselves lies to do things – and I mean “lies” in the most positive sense of the word – then let’s let those lies be small lies so we won’t suffer the full agony of the truth when it comes out. That’s really what Agile is. We set up horizons that are shorter; we build in smaller pieces so that when we feel we’re off course we know it sooner and can do something about it. And that’s the important part: to do something about it.
Be willing to flex
The iron triangle, or project management triangle, states that scope, time, and resources are the three variables in project management. In manufacturing they say pick two and the third must be fixed.
The Iron Triangle
Traditionally people have used the formula Scope = Time * Resources, but this is the wrong approach when building software. In the construction industry, often scope is fixed. You can’t after all release a half completed roof, but in software development, scope is the easiest thing to flex.Developers often build the wrong thing, or overbuild the right thing, so flexing scope should be the first place we look. The most valuable features should be created first, and possibly released early to customers. Given that nearly half of the features delivered are never used, giving the user something instead of nothing can mean the difference between success and failure.
All this leads to shorter feedback cycles. The more feedback you get the more likely you’ll be to identify a problem, and the sooner you get that data the more likely you’ll be able to do something about it.
By working in smaller batches, we’re seeing validations over assumptions.
Agile replaces requirements with stories, and we’ve established that stories are promises for conversations, so what Agile is really saying is that we need to replace requirements with conversations.
Smaller is Better
Agile states that we should mainly measure ourselves on what is valuable to the customer. Bernstein states that this is one of the very few metrics he subscribes to as it discourages local optimization.
The way Bernstein recommends dealing with complex stories is to separate the known from the unknown. We iterate on the unknowns until we make that domain, the domain of the unknowns, smaller and smaller until it simply disappears.
The agile approach of time boxing can be very valuable here. It says: I will take this next iteration to look at this issue and figure out what options are open to me in solving it. Are there libraries that can help me? Can I break it out smaller? What are the key things that I need to know? What do I not know?
The author talks about the modified version of Little’s Law:
Cycle Time = Work in Progress / Throughput
Work in progress, the number of items on our to-do list, divided by the time necessary to complete each item, equals our cycle time.
By reducing the number of items on your to-do list, your cycle time decreases accordingly, providing faster feedback and revealing issues while they’re still small problems that are more easily fixed. Contrasted to waterfall style project management, everything is front loaded onto that list since we do all of our planning up front. This creates for extremely long cycle times.
Whenever you put off integration and testing until later, you’re keeping your work in progress high.Taking a task to 99% completion isn’t good enough because the amount of risk is still unknown. The only way to eliminate the risk associated with adding a new feature is to fully integrate that feature into the system as it is being developed. The solution is to integrate continuously.
Shorten Feedback Cycles
It’s not enough to break tasks down and get more feedback. Developers need constructive feedback that they can take action on. Perhaps most importantly for developers is having a fast automated build that they can depend on for catching errors as they go. This also means that the build and test process should be as short as possible, thereby allowing developers to do it many times a day.
Good software development calls for building the parts and the whole together, but making each part as independent as possible.
Respond to feedback! The Lean Startup movement was created to figure out what the market for something really is.
Build a backlog, which is basically the list of stories we want to build. Order the backlog, don’t prioritize it.
Break stories into tasks. Stories describe an observable behavior in a system, but they may be too involved or too big to do within a two-week iteration. Break it down further into general work items called tasks. The ideal tasks is something that takes about 4 hours to complete.
Don’t use hours for estimating. In an eight hour workday we really get about four ideal hours. So if a task takes about for hours it’s about a day’s work. This is about as small as you can get a task.
Both Extreme Programming and Scrum are akin to nicotine patches in that the real purpose is to try to get teams off the addition of building in releases. Once off that addiction you don’t need the patch anymore. There’s an Agile methodology that embraces that, and it’s called Kanban.
Kanban demands that we limit the number of in progress items, the size of each queue (To Do, In Progress, and Done), but there are no sprints. All this is meant to help you work smarter, not harder, and trying to work on everything all at once is much harder. Work in progress (WIP) limits restrict the number of tasks the team can work on at any given time.
Seven Strategies for Measuring Software Development
Measure time-to-value
Measure time spent coding
Measure defect density
Measure time to detect defects It’s been shown that the cost of fixing defects increases exponentially as time elapses since the defect was created. The cheapest defects to fix are the ones that are detected and fixed immediately after creation.
Measure customer value of features
Measure cost of not delivering features
Measure efficiency of feedback loops A good development process has built-in feedback loops that can be used to tweak the process. The faster the feedback, the more efficient we can become. Find ways to fail fast and learn from failure. This is how teams rapidly improve.
Seven Strategies for Splitting Stories
Break down compound stories into components
Break down complex stories into knowns and unknowns
Iterate on unknowns until they’re understood
Split on acceptance criteria
Minimize dependencies
Keep intentions singular
Keep stories testable
Chapter 7: (Practice 3) Integrate Continuously
Continuous integration is the practice of integrating software as it’s built rather than waiting until just before a release. CI is critical because it not only helps eliminate bugs early but also helps developers learn how to build better code – code that can be integrated more easily.
Developers should be running continuous integration all the time and immediately seeing the results of their efforts on the system, seeing if bugs have been introduced or if their code plays well with the rest of the system.
Establish the Heartbeat of a Project (The Build Server)
The build server sits there and waits for new code to be added to the repository. When it sees new code come in, it goes about automatically rebuilding the whole system. It runs the automated tests, verifies that everything works, and gives you a result.
In addition to the source code, a version control system should version everything else needed to build the system. This includes technical elements like configuration files, database layouts, test code and test scripts, third party libraries, installation scripts, documentation, design diagrams, use case scenarios, UML diagrams, and so on.
The build should happen on the developer’s local machine first. When everything works there, it gets promoted up to the build server. Once the new code is compiled, tests should automatically be run to verify that those changes don’t affect other parts of the system. Tests that take too long to run can move to a nightly build.
Developers should integrate at least once every day. An even better way is to integrate all the time, as soon as you have the tiniest bit of functionality to add.
The first and most important factor in improving software development is to automate the build.
If you take software to only 99% completion, that last 1% can hold an unknown amount of risk. Instead, fully integrate features into the system as they are built.
Seven Strategies for Agile Infrastructure
Use version control for everything
One-click build end-to-end
Integrate continuously
Define acceptance criteria for tasks
Write testable code Once a team commits to automated testing, life becomes a lot less painful, especially for developers who get instant feedback as to whether an approach they’re trying will work. It also encourages devs to start writing code that’s easier to test, which is ultimately higher quality code than untestable code.
Keep test coverage where it’s needed As an idealist, Bernstein strives for 100% test coverage of the behaviors his code creates, even though he knows it isn’t always achievable. Because he writes his tests before he writes his code, he tends to have a high percentage of code coverage.
Fix broken builds immediately
Seven Strategies for Burning Down Risk
Integrate continuously
Avoid branching
Invest in automated tests
Identify areas of risk
Work through unknowns
Build the smallest pieces that show value
Validate often
Chapter 8: (Practice 4) Collaborate
When you’re working as a team it’s not enough to be on the team – a member of the team or somehow “team adjacent” – you really have to be in the team – immersed in that culture. Teams that are more productive are often more collaborative. They’re able to look up and see their colleagues, ask a question, answer a question, or discuss a question.
Extreme programming does away with cubicles in favor of shared desks and a more communal setting, free of private spaces.
Pair Programming
Software development is more than a technical activity. It’s also a social activity. Team members must be able to communicate complex abstract ideas and work well together. Communication depends more on common understanding than common workspace. One of the most valuable of Extreme Programming practices is that of pair programming, where two devs work on the same task together on one computer. Pairing is not about taking turns at the computer, but about bringing two minds to bear on the same task so that task is completed more rapidly and at a much greater level of quality than if one person worked on it alone. Software devs can get a lot more accomplished when they work together than when they work alone.
Pair programming disseminates knowledge across a team far more quickly than any other method, and it creates for a notion of collective code ownership. It will also cause developers to get more done writing less code, which also drops the cost of maintenance, but will also create a huge decrease in the amount of bugs written, which will dramatically speed up the time to delivery.
As a step towards pair programming, people can try buddy programming, where you work by yourself for most of the day, then spend the last hour of the day getting together with a buddy and do a code review of what you both did that day.
Spiking is when two or more developers focus on a single task together, usually working for a predefined length of time to resolve some kind of unknown.
Swarming is when the whole team, or small groups of more than two members each, work together on the same problem, but they’re all working simultaneously.
Mobbing is when the whole team normally works together on a single story, like a swarm of ants working together to break down a piece of food.
In the thinking of extreme programming, if code reviews are a good thing, why don’t we review every line of code as we’re writing it? That’s where the pair programming came from; it’s an extreme version of a code review.
Always strive to be mentoring and mentored.
Seven Strategies for Pair Programming
Try it You won’t know if you like it unless you try it.
Engage drive and navigator Pairing is not about taking turns doing the work. Each member has specific duties, working together, and in parallel. Both the person at the keyboard (the driver) and the one looking over the driver’s shoulder (navigator) are actively engaged while pairing.
Swap roles frequently
Put in an honest day Pairing takes a lot of energy. You are “on” and focused every minute of the day.
Try all configurations Try random pairing but story, task, hour, all the way down to twenty minutes. Often, people who wouldn’t think to pair with each other make the best and most productive pairs.
Let teams decide on the details Pair programming – like any of the Agile practices – cannot be forced on a team by management. Team members have to discover the value for themselves.
Track progress
Seven Strategies for Effective Retrospectives
Look for small improvements
Blame process, not people
Practice the five whys When faced with a problem, ask why it happened, or what caused it to happen, and with that answer ask why that happened, and so on, until you’ve asked “why” at least five times. After about the fourth “why” you’ll often start to discover some interesting problems you may not have been aware of.
Address root causes
Listen to everyone Retrospectives should engage everyone on a team. Don’t just let the most vocal team members get all the say. Instead, solicit opinions from everyone and give everyone actionable objectives for making small improvements.
Empower people Give people what they need to make improvements. Demonstrate to people that you are serious about continuous improvement and support them making changes. If people fear making changes it’s generally because they feel unsupported. Show them that you encourage and reward this kind of initative.
Measure progress
Chapter 9: (Practice 5) Create CLEAN Code
This chapter is a short overview of Uncle Bob Martin’s Clean Code. He talks about quantifiable code qualities, which are little things that can make a big difference. An object should have well-defined characteristics, focused responsibilities, and hidden implementation. It should be in charge of its own state, and be defined only once.
C ohesive L oosely Coupled E ncapsulated A ssertive N onreduntant
Quality Code is Cohesive
High quality code is cohesive, that is, each piece is about one and only one thing. To software developers cohesion means software entities (classes and methods) should have a single responsibility.
Our programs should be made up of lots and lots of little classes that will have very limited functionality.
When we have cohesive code, if a change is required, it will likely only be focused on one or a few classes, making the change easier to isolate and implement.
Good object-oriented programs are like ogres, or onions: they have layers. Each layer represents a different level of abstraction.
In order to model complex things, use composition. For example, a person class would be composed of a class for walking, a talking class, an eating class, and so on. The walking class would be composed of a class for balance, a forward step class, and so on.
Quality Code is Loosely Coupled
Code that is loosely coupled indirectly depends on the code it uses so it’s easier to isolate, verify, reuse and extend. Loose coupling is usually achieved through the use of an indirect call. Instead of calling a service directly, the service is called through an intermediary. Replacing the service call later will only impact the intermediary, reducing the impact of change on the rest of the system. Loose coupling lets you put seams into your code so you can inject dependencies instead of tightly coupling to them.
Rather than call a service directly you can call through an abstraction such as an abstract class. Later you can replace the service with a mock for testing or an enhanced service in the future with minimal impact on the rest of the system.
Quality Code is Encapsulated
Quality code is encapsulated – it hides its implementation details from the rest of the world. One of the most valuable benefits of using an object oriented language over a procedural language is its ability to truly encapsulate entities. By encapsulation, I don’t just mean making state and behavior private. Specifically, I want to hide interface (what I’m trying to accomplish) from implementation (how I accomplish it). This is important because what you can hide you can change later without breaking other code that depends on it.
“Encapsulation is making something which is varying appear to the outside as if it’s not varying.”
Quality Code is Assertive
Quality code is assertive – it manages its own responsibilities. As a rule of thumb, an object should be in charge of managing its own state. In other words, if an object has a field or property then it should also have the behavior to manage that field or property. Objects shouldn’t be inquisitive, they should be authoritative – in charge of themselves.
Quality Code is Nonredundant
DRY – don’t repeat yourself. 95% of redundant code is duplicated code, which is the phrase used in extreme programming, but the other 5% is code that’s functionality doing the same thing despite slightly different implementations. Nonidentical code can be redundant; redundancy is a repetition of intent.
Code Qualities Guide Us
When code is cohesive it’s easier to understand and find bugs in it because each entity is dealing with just one thing.
When code is loosely coupled we find fewer side effects among entities and it’s more straightforward to test, reuse and extend.
When code is well encapsulated it helps us manage complexity and keep the caller out of the implementation details of the callee – the object being called – so it’s easier to change later.
When code is assertive it shows us that often the best place to put behavior is with the data it depends on.
When code is nonredundant it means we’re dealing with bugs and changes only once and in one location.
Quality code is Cohesive, Loosely coupled, Encapsulated, Assertive, and Nonredundant, or CLEAN for short.
Code that lacks these qualities is difficult to test. If I have to write a lot of tests for a class I know I have cohesion issues. If I have lots of unrelated dependencies, I know I have coupling issues. If my test are implementation dependent, I know I have encapsulation issues. If the results of my test are in a different object that he one being tests, I probably have assertiveness issues. If I have to write the same test over and over, I know I have redundancy issues.
Testability then becomes the yardstick for measuring the quality of a design or implementation.
Bernstein states that when faced with two approaches that seemed equally valid, he will also go with the one that is easier to test, because he knows it’s better.
Ward Cunningham coined the term technical debt to express what can happen when developers don’t factor their learning back into their code as they’re building it. Nothing slows development down and throws off estimates more than technical debt.
Bernstein has a friend who says “I don’t have time to make a mess”, because he knows working fast is working clean.
Seven Strategies for Increasing Code Quality
Get crisp on the definition of code quality
Share common quality practices
Let go of perfectionism
Understand trade-offs
Hide “how” with “what”
Name things well Name entities and behaviors for what they do, not how they do it.
Keep code testable.
Seven Strategies for Writing Maintainable Code
Adopt collective code ownership
Refactor enthusiastically
Pair constantly Pair programming is the fastest way to propagate knowledge across a team.
Do code reviews frequently
Study other developers’ styles
Study software development
Read code, write code, and practice coding
Chapter 10: (Practice 6) Write the Test First
Tests are specifications, they define behavior. Write just enough tests to specify the behaviors you’re building and only write code to make a failing test pass.
Acceptance Tests = Customer Tests
Unit Tests = Developer Tests
Other Tests (Integration Tests) = Quality Assurance Tests
Unlike unit tests that mock out all dependencies, integration tests use the real dependencies to test the interaction of components, making the test more brittle and slower.
When you start seeing test-first development as a way of specifying behaviors rather than verifying behaviors, you can get a lot clearer on what tests you need. Writing tests after you write the code also often reveals that the code you wrote is hard to test and requires significant cleaning up to make testable, which can become a major project. It’s better to write testable code in the first place, and the simplest way to write testable code is to write it test-frst.
One of the other significant benefits of writing a test first is that you’re only going to write code covered by tests and so will always have 100% code coverage.
Writing code to make a failing test pass assures that you’re building testable code since it’s very hard to write code to fulfill a test that’s untestable. One of the biggest challenges we have as developers is that we tend to write code that’s not inherently testable. Then, when we go to try to test it alter, we find ourselves having to redesign and rewrite a lot of stuff.
Tests play a dual role. On one hand it’s a hypothesis – or a specification for a behavior – and on the other hand, it’s a regression test that’s put in place and is always there, serving us by verifying that the code works as expected.
Keep in mind that unit tests test units of behavior – an independent, verifiable behavior. It must create an observable difference in the system and not be tightly coupled to other behaviors in the system. It means that every observable behavior should have a test associated with it.
The cheapest way to develop software is to prevent bugs from happening in the first place, but the second cheapest way is to find them immediately so they’re fixed by the same person or team that wrote them rather than fixed later by a different team entirely.
TDD supports refactoring, as code that’s supported by unit tests is safer to refactor. That’s because if you make a mistake, it’ll likely cause one of your tests to fail, so you’ll know about it immediately and can fix it right away.
“In TDD there’s always something I can do to stay productive. I can clean up code or write another test for new behavior; I can break down a complex problem into lots of smaller problems. Doing TDD is like having a difficulty dial, and when I get stuck I can always dial it down to ‘pathetically simple’ and stay there a little while until I build up confidence and feel ready to turn the dial up to raise the difficulty. But all the while, I’m in control.”
TDD can also fail if done improperly. If you write too many tests, and therefore write tests that test against implementation – the way something is done – instead of testing against interface – what they want done- it will fail. Remember, unit tests are about supporting you in cleaning up code, so we have to write tests with supportability in mind.
Unit test are only meant to test your unit of behavior.
If you interface with the reset of the world, you need to mock out the rest of the world so that you’re only testing your code.
Developers should start with the what because that’s what the interface is. That’s what the test is. The test is all about the what.
Seven Strategies for Great Acceptance Tests
Get clear on the benefits of what you’re building Writing acceptance tests forces you to get clear on exactly what you’re building and how it will manifest in the system.
Know who it’s for and why they want it. This can help developers find better ways of accomplishing a task so that it’s also more maintainable.
Automate acceptance criteria
Specify edge cases, exceptions, and alternate paths
Use examples to flesh out details and flush out inconsistencies Working through an example of using a feature is a great way to start to understand the implementation issues around that feature.
Split behaviors on acceptance criteria Every acceptance test should have a single acceptance criterion that will either pass or fail.
Make each test unique
Acceptance tests tell developers what needs to be built, and most importantly, when they’ll be done.
Seven Strategies for Great Unit Tests
Take the caller’s perspective Always start the design of a service from the callers perspective. Think in terms of what the caller needs and what it has to pass in.
Use tests to specify behaviors
Only write tests that create new distinctions
Only write production code to make a failing test pass
Build out behaviors with tests
Refactor code
Refactor tests
A good set of unit tests provides regression and supports developers in safely refactoring code.
Chapter 11: (Practice 7) Specify Behaviors with Tests
The three distinct phases of TDD are red, green, refactor. Meaning you write a test first that is failing, you then write code to make the test pass, and you then refactor.
Start with stubs, a method that just returns a dummy value instead of doing actual calculations, and then add actual behaviors and constraints.
Think of unit tests as specifications. It’s difficult or even impossible to tell if a requirements document is out of date, but with the click of a button you can run all of your unit tests and verify that all of your code is up to date. They’re living specifications.
Make each test unique.
Test driven development is a design methodology. It helps developers build high quality code by forcing them to write testable code and by concretizing requirements.
Unit tests can be useful for specifying parameters, results, how algorithms should behave, and many other things, but they can’t test that a sequence of calls are in the right order, or other similar scenarios. For that you need another kind of testing called workflow testing.
Workflow testing uses mocks, or stand-ins for real objects. Anything that’s external to the code you’re testing needs to be mocked out.
Seven Strategies for Using Tests as Specifications
Instrument your tests Instead of using hard coded values as parameters, assign those values to variables that are named for what they represent. This makes generalizations explicit so the test can read like a specification.
Use helper methods with intention-revealing names Wrap setup behavior and other chunks of functionality into their own helper methods.
Show what’s important Name things for what’s important. Call out generalizations and key concepts in names. Say what the test exercises and state it in the positive.
Test behaviors, not implementations Tests should exercise and be named after behaviors and not implementations. testConstructor is a bad name; tesetRetrievingValuesAfterConstruction is better. Use long names to express exactly what the test is supposed to assert.
Use mocks to test workflows.
Avoid overspecifying
Use accurate examples
Seven Strategies for Fixing Bugs
Don’t write them in the first place
Catch them as soon as possible
Make bugs findable by design Your ability to find bugs in code is directly related to the code’s qualities. For example, software that is highly cohesive and well encapsulated is less likely to have side effects that can cause bugs.
Ask the right questions
See bugs as missing tests
Use defects to fix process When you find a bug, ask why the bug happened in the first place. Often times this leads back to a problem in the software development process, and fixing the process can potentially rid you of many future bugs.
Learn from mistakes If bugs represent false assumptions or flaws in our development process, it’s not enough to simply fix the bug. Instead, fix the environment that allowed the bug to happen in the first place. Use bugs as lessons on vulnerabilities in your design and process so you can look for ways to fix them. Use mistakes as learning opportunities and gain the valuable message each of our problems hold.
Chapter 12: (Practice 8) Implement the Design Last
Common developer practices that can be impediments to change:
Lack of encapsulation The more one piece of code “knows” about another, the more dependencies it has, whether it’s explicit or implicit. This can cause subtle and unexpected problems where one small change can break code that’s seemingly unrelated.
Overuse of inheritance
Concrete implementations
Inlining code
Dependencies
Using objects you create or creating objects you use To instantiate an object, you need to know a great deal about it, and this knowledge breaks type encapsulation – users of the code must be aware of sub-types – and forces callers to be more dependent on a specific implementation. When users of a service also instantiate that service, they become coupled to it in a way that makes it difficult to test, extend, or reuse.
Tips for writing sustainable code
Delete dead code dead code serves no purpose except to distract developers. Delete it.
Keep names up to date.
Centralize decisions
Abstractions Create and use abstractions for all external dependencies, and create missing entities in the model because, again, your model should reflect the nature of what you’re modelling.
Organize classes
Bernstein finds it helpful to distinguish between coding and cleaning, and treat them as separate tasks. When he’s coding he’s looking for solutions to a specific task at hand. When he’s cleaning he’s taking working code and making it supportable. Coding is easier when he’s focused on just getting a behavior to work and his tests to pass. Cleaning is easier when he has working code that’s supported with tests and he can focus on making the code easier to understand and work with.
Pay off technical debt both in the small – during the refactoring step of test-first development – and in the large – with periodic refactoring efforts to incorporate the team’s learning into the code.
On average, software is read 10 times more than it’s written, so write your code for the reader (someone else) as opposed to the writer (yourself). Software development is not a “write once” activity. It is continually enhanced, cleaned up, and improved.
Use intention revealing names instead of comments to convey the meaning of your code. You may want to use comments to describe why you’re doing something, but don’t use them to describe what you’re doing. The code itself should say what it’s doing. If you find yourself writing a comment because you don’t think a reader will understand what’s going on just by reading the code, you should really consider rewriting the code to be more intention revealing.
Program by intention
Programming by intention: Simply delegate all bits of functionality to separate methods in all your public APIs. It gives your code a cohesion of perspectives, meaning that all the code is at the same level of abstraction so it’s easier to read and understand.
Think of object-oriented code in layers. This is how we naturally think. If we think about the high-level things we need to do today, we’re not thinking about all the little details. Then, when we think about how we’re going to do that step, we unfold the top layer and start looking at the details. Understand and look at code the same way, with those levels of abstraction.
When you look at the how, when you jump into that level inside the what, you find a bunch more whats that have to happen to implement that how. That’s how to think about the whats, and it delegates the how to others and so on until you work down the chain.
Reduce Cyclomatic Complexity
Cyclomatic complexity represents the number of paths through code. Code with just one conditional or if statement has a cyclomatic complexity of two – there are two possible paths through the code and therefore two possible behaviors the code can produce. If there are no if statements, no conditional logic in code, then the code has a cyclomatic complexity of one. This quantity grows exponentially: if there are two if statements the cyclomatic complexity is four, if there are three it is eight, and so on. Drive the cyclomatic complexity down to as low as you can because, generally, the number of unit tests needed for a method is at least equal to its cyclomatic complexity.
Correspondingly, the higher the cyclomatic complexity, the higher the probability that it will have bugs. If you build each entity with a low cyclomatic complexity, you need far fewer tests to cover your code.
Separate Use from Creation
Use factories to separate the instantiation of an object from the usage of that object.
Polymorphism allows you to build blocks of code independent of each other so they can grow independently from each other. For example, when someone comes up with a new compressor that was never envisioned before, the existing code can automatically take advantage of it because it’s not responsible for selecting the compressor to use. It’s just responsible for delegating to the compressor it’s given. In order to do this correctly though, you need to create objects separately, in a different entity than the entity that’s using the objects. By isolating object creation we also isolate the knowledge about which concrete objects are being used and hide it from other parts of the system.
Emergent Design
As you pay attention to the challenges you’re having as you’re building software, those challenges are actually indicating that there’s a better way to do something. This allows you to take things like bugs, the pain, nagging customers not getting what they want, and turn them into assets. They hold the clues to how to do things so much better. If you use the information you’re getting in that way, they’re really blessings in disguise.
Seven Strategies for Doing Emergent Design
Understand object-oriented design Good object-oriented code is made up of well-encapsulated entities that accurately model the problem it’s solving.
Understand design patterns Design patterns are valuable for managing complexity and isolating varying behavior so that new variations can be added without impacting the rest of the system. Patterns are more relevant when practicing emergent design than when designing up front.
Understand test-driven development
Understand refactoring Refactoring is the process of changing one design to another without changing external behavior. It provides the perfect opportunity to redesign in the small or in the large with working code. Bernstein does most of his design during refactoring once he’s already worked out what needs to be done. This allows him to focus on doing it well and so that the right design can emerge.
Focus on code quality CLEAN – cohesive, loosely coupled, encapsulated, assertive, and nonredundant.
Be merciless Knowing the limits of a design and being willing to change it as needed is one of the most important skills for doing emergent design.
Practice good development habits To create good designs, first understand the principles behind the practices of Extreme Programming and Agile, and make good development practices into habits.
Seven Strategies for Cleaning Up Code
Let code speak for itself Write code clearly using intention-revealing names so it’s obvious what the code does. Make the code self-expressive and avoid excessive comments that describe what the code is doing.
Add seams to add tests One of the most valuable things to do with legacy code is add tests to support further rework. Look to Michael Feathers’ book Working Effectively with Legacy Code for examples of adding seams.
Make methods more cohesive Two of the most important refactorings are Extract Method and Extract Class (look to Refactoring by Martin Fowler). Method are often made to do too much.Other methods and sometimes entire classes can be lurking in long methods. Break up long methods by extracting new methods from little bits of functionality that you can name. Uncle Bob Martin says that ideally methods should be no longer than four lines of code. While that may sound a bit extreme, it’s a good policy to break out code into smaller methods if you can write a method name that describes what you’re doing.
Make classes more cohesive Another typical problem with legacy code is that classes try to do too much. This makes them difficult to name. Large classes become coupling points for multiple issues, making them more tightly coupled than they need to be. Hiding classes within classes gives those classes too many responsibilities and makes them hard to change later. Breaking out multiple classes makes them easier to work with and improves the understandability of the design.
Centralize decisions Try to centralize the rules for any given process. Extract business rules into factories if at all possible. When decisions are centralized, it removes redundancies, making code more understandable and easier to maintain.
Introduce polymorphism Introduce polymorphism when you have a varying behavior you want to hide. For example, I may have more than one way of doing a task, like sorting a document or compressing a file. If I don’t want my callers to be concerned with which variation they’re using, then I may want to introduce polymorphism. This lets me add new variations later that existing clients can use without having to change those clients.
Encapsulate construction An important part of making polymorphism work is based on clients using derived types through a base type. Clients call sort() without knowing which type of sort they’re using. Since you want to hide from clients the type of sort they’re using, the client cant instantiate the object. Give the object the responsibility of instantiating itself by giving it a static method that invokes new on itself, or by delegating that responsibility to a factory.
Chapter 13: (Practice 9) Refactor Legacy Code
Refactoring is restructuring or repackaging the internal structure of code without changing its external behavior.
Software by its very nature is high risk and likely to change. Refactoring drops the cost of four things:
comprehending the code later
adding unit tests
accommodating new features
and doing further refactoring
By making incremental changes, adding tests, and then adding new features, legacy code gets cleaned up in a systematic manner without fear of introducing new bugs.
Refactoring Techniques
Pinning Tests – A very coarse test. It may test a single behavior that takes hundreds or thousands of lines of code to produce. Ultimately you want more tests that are smaller tests than this, but start by writing a pinning test for your overall behavior so that at least you have some support in place. Then as you make changes to the code, you rerun the pinning test to verify that the end-to-end behavior is still correct.
Dependency Injection – Instead of creating the objects we use ourselves, we let the framework create them for us and inject them into our code. Injecting dependencies as opposed to creating them decouples objects from the services they use.
System Strangling – Wrap an old service with your new one and let it slowly grow around the old one until eventually the old system is strangled. Create a new interface for a new service that’s meant to replace an old service. Then ask new clients to use the new interface, even though it simply points to the old service. This at least stops the bleeding and allows new clients to use a new interface that will eventually call cleaner code.
Branch by Abstraction – Extract an interface for the code you want to change and write a new implementation, but keep the old implementation active while you build it. , using feature flags to hide the feature that’s under development from the user while you’re building it.
Refactor to Accommodate Change
Clean up legacy code, make it more maintainable and easier to understand, and then retrofit in tests to make it safer to change. Then, and only then, with the safety of unit tests, refactor the code in more significant ways.
Refactor the the Open-Closed
The open-closed principle says software entities should be “open for extension but closed for modification.” In other words, strive to make adding any new feature a matter of adding new code and minimally changing existing code. Avoid changing existing code because that’s when new bugs are likely to be introduced.
Refactor to Support Changeability
Changeability in code does not happen by accident. It has to be intentionally created in new code, or carefully introduced in refactoring legacy code, by following good developer principles and practices. Supporting changeability in code means finding the right abstractions and making sure code is well encapsulated.
“Do it right the second time.“
Seven Strategies for Helping you Justify Refactoring
To learn an existing system
To make small improvements
To retrofit tests in legacy code
Clean up as you go
Redesign an implementation once you know more
Clean up before moving on
Refactor to learn what not to do
Seven Strategies for When to Refactor
When critical code is not well maintained
When the only person who understands the code is becoming unavailable
The Gang of Four state that the abstract factory design pattern is used to “provide an interface for creating families of related or dependent objects without specifying their concrete classes.”
Abstract factories provide an interface for creating a family of products. By writing code that uses this interface we can decouple our code from the actual factory that creates the products. This allows us to implement a variety of factories that create products meant for different contexts. This decoupling aspect is what makes abstract factories so useful.
In the example below, adapted from riptutorial, we will look at the case of creating a GUI for Windows and Linux environments. In this example, the code is decoupled from the actual products, which means we can easily substitute different factories to get different behaviors. We create two concrete implementations of the GUIFactory class, which itself is composed of factory methods, one for windows operating systems, and another for linux operating systems. We then use the generic interface created by the GUIFactory class to create concrete objects.
Because this is modern C++, we use unique_ptr pretty liberally.
/* abstract_factory_example.cpp */
#include <iostream>
#include <memory>
#include <string>
/* GUIComponent abstract base class */
class GUIComponent {
public:
virtual ~GUIComponent() = default;
virtual void draw() const = 0;
};
class Frame : public GUIComponent {};
class Button : public GUIComponent {};
class Label : public GUIComponent {};
class ScrollBar : public GUIComponent {};
class LinuxFrame : public Frame {
public:
void draw() const override {
std::cout << "I'm a Linux frame" << std::endl;
}
};
class LinuxButton : public Button {
public:
void draw() const override {
std::cout << "I'm a Linux button" << std::endl;
}
};
class LinuxLabel : public Label {
public:
void draw() const override {
std::cout << "I'm a Linux label" << std::endl;
}
};
class LinuxScrollBar : public ScrollBar {
public:
void draw() const override {
std::cout << "I'm a Linux scrollbar" << std::endl;
}
};
class WindowsFrame : public Frame {
public:
void draw() const override {
std::cout << "I'm a Windows frame" << std::endl;
}
};
class WindowsButton : public Button {
public:
void draw() const override {
std::cout << "I'm a Windows button" << std::endl;
}
};
class WindowsLabel : public Label {
public:
void draw() const override {
std::cout << "I'm a Windows label" << std::endl;
}
};
class WindowsScrollBar : public ScrollBar {
public:
void draw() const override {
std::cout << "I'm a windows scrollbar" << std::endl;
}
};
/* Abstract factory abstract base class
* Note: abstract factories can also be concrete
*/
class GUIFactory {
public:
virtual ~GUIFactory() = default;
/* create_frame factory method */
virtual std::unique_ptr<Frame> create_frame() = 0;
/* create_button factory method */
virtual std::unique_ptr<Button> create_button() = 0;
/* create_label factory method */
virtual std::unique_ptr<Label> create_label() = 0;
/* create_scrollbar factory method */
virtual std::unique_ptr<ScrollBar> create_scrollbar() = 0;
/* create static method to select which concrete factory to instantiate */
static std::unique_ptr<GUIFactory> create(const std::string& type);
};
/* Concrete windows factory */
class WindowsFactory : public GUIFactory {
public:
std::unique_ptr<Frame> create_frame() override {
return std::make_unique<WindowsFrame>();
}
std::unique_ptr<Button> create_button() override {
return std::make_unique<WindowsButton>();
}
std::unique_ptr<Label> create_label() override {
return std::make_unique<WindowsLabel>();
}
std::unique_ptr<ScrollBar> create_scrollbar() override {
return std::make_unique<WindowsScrollBar>();
}
};
/* Concrete Linux factory */
class LinuxFactory : public GUIFactory {
public:
std::unique_ptr<Frame> create_frame() override {
return std::make_unique<LinuxFrame>();
}
std::unique_ptr<Button> create_button() override {
return std::make_unique<LinuxButton>();
}
std::unique_ptr<Label> create_label() override {
return std::make_unique<LinuxLabel>();
}
std::unique_ptr<ScrollBar> create_scrollbar() override {
return std::make_unique<LinuxScrollBar>();
}
};
/* create static method to select which type of factory to use */
std::unique_ptr<GUIFactory> GUIFactory::create(const std::string& type) {
if (type == "windows") return std::make_unique<WindowsFactory>();
return std::make_unique<LinuxFactory>();
}
/* build_interface function that takes in an abstract factory as a param*/
void build_interface(GUIFactory& factory) {
auto frame = factory.create_frame();
auto button = factory.create_button();
auto label = factory.create_label();
auto scrollbar = factory.create_scrollbar();
frame->draw();
button->draw();
label->draw();
scrollbar->draw();
}
int main(int argc, char *argv[]) {
if (argc < 2) return 1;
auto guiFactory = GUIFactory::create(argv[1]);
build_interface(*guiFactory);
}
We’ll compile this quick with a simple g++ invocation:
One of the easiest ways to ensure loose coupling between objects in C++ is to use abstract base classes to define an interface, and then use that interface in other classes.
Let’s define a simple FilterInterface abstract base class that defines the interface for subsequent filter classes, which will then be used as a component of an ADC class.
#include <iostream>
#include <vector>
class FilterInterface {
public:
virtual ~FilterInterface() {}
virtual void reset() = 0;
virtual void update(int a, int b) = 0;
virtual int get_a() = 0;
virtual int get_b() = 0;
protected:
int a_{1};
int b_{1};
};
class AverageFilter : public FilterInterface {
public:
void reset() override final{
a_ = 0;
b_ = 0;
}
void update(int a, int b) override final {
a_ = a;
b_ = b;
}
int get_a() override final {
return a_;
}
int get_b() override final {
return b_;
}
};
class ADC {
public:
ADC(FilterInterface& interface) : interface(interface) {
interface.reset();
}
void process() {
interface.update(10, 20);
}
std::vector<int> get_values() {
std::vector<int> vec;
vec.push_back(interface.get_a());
vec.push_back(interface.get_b());
return vec;
}
protected:
FilterInterface& interface;
};
int main() {
AverageFilter filter;
std::cout<<"filter.a = "<<filter.get_a()<<", filter.b = "<<filter.get_b()<<std::endl;
std::cout<<"Constructing adc object"<<std::endl;
ADC adc(filter);
std::vector<int> vec = adc.get_values();
std::cout<<"adc.interface.a = "<<vec[0]<<", adc.interface.b = "<<vec[1]<<std::endl;
std::cout<<"calling process method"<<std::endl;
adc.process();
vec = adc.get_values();
std::cout<<"adc.interface.a = "<<vec[0]<<", adc.interface.b = "<<vec[1]<<std::endl;
}
First, we declare the abstract base class FilterInterface by declaring pure virtual functions. We then inherit from it to create the derived class AverageFilter. The class ADC then takes in a reference to something that is FilterInterface like, or at least uses the interface defined by it. This allows us to have the ADC class decoupled from the implementation details of child classes of FilterInterface, and we can pass in a references to other child classes of it. This way, if we decide we need to change the filter that’s used in ADC, and want to use, let’s say some class we called SavitzkyGolayFilter, it’s easy peasy.
If we compile and run the executable above we get the following output:
Recently at work our network admin revealed that he thought he needed to domain join all of the Ubuntu users to be able to recover their passwords in the event that someone forgot theirs… Little did he know it’s as simple as booting in single user mode (rescue mode), executing a few commands and then restarting.
Single User Mode
On Ubuntu and Debian systems, the single user mode, also referred to as the rescue mode, is used to perform critical operations, like resetting a lost password or perform file system checks and repairs if your system is unable to mount them. Simply put, it allows a multiuser computer OS to boot into a single superuser.
Resetting a Lost Password With Single User Mode
First you will need to access the GRUB console to make some changes. As soon as the boot process starts, press ESC to bring up the GRUB boot prompt (if you’re using UEFI BIOS).
Select the boot option you would like to boot into and press ‘e’ to edit it.
Find the kernel line (the line starting with linux /boot/) and append init=/bin/bash to the end of the line. Alternatively, you can change the ro portion of the line ending to rw and add init=/bin/bash to the end of it to allow you to skip remounting with read+write capabilities. Note: Before appending the string remove the word “$vt_handoff” if it exist in the line that begins with “linux”.
Press CTRL+X or F10 to boot with these new, edited options.
Once the system boots you will see the root prompt. If you haven’t changed ro to rw as part of your boot options, you will need to invoke mount -o remount,rw /
At this point you have read+write abilities with the root profile, so all you have to do is invoke passwd <username> to change a particular user’s password, or simply passwd to change the current user’s password (in this case, root).
After making all of the changes you want, it’s now time to reboot the system. Type exec /sbin/init to reboot, or alternatively reboot and you’re all done!
Github actions allow you to start workflows triggered by events like pushing, issue creation, or new releases. One super common thing they allow you to do is build and test your code using hosted runners (or local runners if you prefer) whenever you push code to your remote repository, and then display a pretty badge indicating the status of those workflows.
As David Scott Bernstein puts it in Beyond Legacy Code, “If software is to be used it will need to be changed, so it must be written to be changeable.” And whats the best way to make sure you haven’t broken everything by changing your code? You got it, automated unit and integration tests. Bernstein in fact dedicates nearly half of Beyond Legacy Code to the notions of continuous integration and testing with 4 of his 9 practices to avoid creating legacy code being “Integrate Continuously”, “Write the Test First”, “Specify Behaviors With Tests” and “Refactor Legacy Code”.
Let’s Make a Workflow!
Let’s use my super simple simple_example_projects repo as the example here, where I’ve already created some pretty basic gtests for the TicTacToe game. To create a new workflow, simply head over to the “Actions” tab, and click “New Workflow”.
I then chose the “C/C++ with Make” starter workflow, under the “Continuous integration workflows” heading as my starting point. This gives you a basic boilerplate YAML file to start your action from.
This will then show you a YAML that’s populated like this:
We’ll go ahead and modify it a bit so that we’re installing gtest every time a runner kicks off:
You don’t need to see all the implementation details since you can just go right to my github to take a look at it, but what we’ve done is named this particular action “Unit Tests”, told it to execute when we push to main or submit a pull request to main, that it runs on ubuntu-latest, and then specified 4 individual steps for it to perform:
Install gtest manually
Configure (invokes cmake)
make
Run tests
These are the names that are used when you check on your workflow status.
You can then easily expand each of these items to see what occurred and what the output was:
Finally, adding those fancy badges is as simple as going to your README.md file and inserting the following:

The thing to note here is the pattern that should be used for displaying your badge: .
And there you have it! A fast, easy way to provide automated builds using a remote server provided by Github.
Billing for GitHub Actions
One final thing to note is that GitHub Actions usage is free for both public repositories and self-hosted runners, at least at the time of writing this as per here. For private repositories, each GitHub account receives a certain amount of free minutes and storage, depending on the product used with the account. To see how long your actions are taking, simply take a look at your workflows page:
If you are using GitHub Free you’ll be allowed 500MB of storage and 2,000 minutes per month, whereas if you’re using Pro or Team, you’ll be afforded 1 GB of storage and 3,000 minutes per month.
One final gotcha is that jobs run on Windows and macOS runners that GitHub hosts consume minutes at 2 and 10 times the rate that jobs on Linux runners consume. So, if you using 1,000 Windows minutes you will have consumed 2,000 of your allotted minutes, if you use 1,000 macOS minutes, you will have consumed 10,000 of your allotted minutes.
If you go over your allocated minutes in a month they’ll start charging you extra (if you’ve allowed for this, by default it’s disabled unless you pay by invoice), but the price is relatively low (0.8 cents per minute on Linux) and the allowed minutes for most users is higher than they’d need unless they’re in a professional setting.
This paper serves as a high level overview of previous work I led involving the control law synthesis for a nonlinear, coupled, hydraulically actuated robot manipulator.
A literature survey has been performed to understand currently used techniques for hydraulic control of robot manipulators, the results of which will be outlined in section 2. In section 3 a controls strategy will be presented that has been designed in light of the literature survey, and section 7 highlights simulation results of the designed control law.
2. Literature Survey
The most common approach encountered in the literature for stationary manipulators is feedback linearization via inverse dynamics, coupled with an outer PD position control loop, and an inner torque loop.
The work regarding the HyQ robot is interesting because the authors take the time to derive relations that other papers do not.[1] In their paper, the authors used feedback linearization via inverse dynamics, with an outer position loop and an inner torque loop. High performance servo-valves with a bandwidth of ~250hz are used. The position loop is closed with 80,000 PPR encoders, while the torque loop is closed with a load-cell measuring the cylinder force. Both control loops run at 1 kHz. Joint torques are computed by multiplying the cylinder force by the actual lever arm.
Practically speaking, the torque loop was able to provide a bandwidth of 40 hz. The electrohydraulic system is modeled by employing the continuity equation at the valve + actuator sub-system level (1).
where is the fluid density, t is time, and u is the flow velocity vector field.
By applying force and flow balance, and neglecting hydraulic viscous friction, the dynamics of the hydraulic force are described as:
The valve command u is governed by a control law, v, which is chosen to be a PID control law. The torque control law uses seven states: the cylinder position, xp, cylinder velocity, , the cylinder A side chamber pressure, Pa, cylinder B side chamber pressure, Pb, the supply pressure, Ps, the tank pressure Pt, and torque, . The position control law uses only position feedback. The inverse dynamics term is governed by a reference angular acceleration (reference trajectory shaping), and feedback angular position and angular velocity. The largest control effort is exerted by the inverse dynamics term.
Feng used model predictive control with inverse dynamics and inverse kinematic high level control, with joint level torque controllers with parameters specified by Boston Dynamics. [2]
Overviews of the HyQ design used a patched real time linux kernel (xenomai), in conjunciton with Simulation Laboratory developed by the computation learning motor control lab at USC. They ultimately conclude PID control is insufficient for their control goals. [3] SL, the simulation and real-time control software package is detailed in [4].
Sirouspour et al. use the generalized actuator dynamics equation (2) listed above to model their 3-way valve dynamics. They discuss the use of an augmented error inverse dynamics back-stepping controller, as well as an adaptive variant with lyapunov based adaptation law. The controller is implemented using the matlab real time workshop toolbox with custom parallel I/O comms and a 512 hz controller frequency. Passivity and sliding observers are used to avoid acceleration measurement. The derivation of and for the actuator dynamics are included in an appendix, where the A and B pressures, and valve spool position are used as states. [5]
Cunha et al. show that a gain scheduled PID controller is insufficient for the hydraulically actuated HyQ robot leg. Actuator dynamics modelling is included which is based on Bernoulli’s equation (orifice flow rate). Proportional valves with overlap and a bandwidth of 30-40 hz were used. Proportional flow metering in the spool valves is used with a 2 kHz PWM signal. A 1 kHz control loop frequency is used. [6]
Habibi et al. used a computed torque sliding mode controller with a sampling frequency of 500 hz. Again, the largest control effort is exerted by the inverse dynamics term, as was shown with the HyQ leg. The authors conclude very good control was achieved with their approach. Pressure feedback is used and a thorough derivation of the actuator models are included. [7]
In the Matilla et al. survey, all nonlinear controllers outperformed the best linear controllers; a performance indicator, , was used to compare controls studies. The authors indicate all surveyed papers reported variable displacement pumps having a response time between 40 and 130ms, whereas cutting-edge servovalves had a response time of ~1.8 ms. The authors indicate actuator dynamics must be included in hydraulic systems as they are highly nonlinear. They list use of Lyuaponov methods, L2 and L-infinity stability analysis, sliding mode control, adaptive inverse dynamics, adaptive inverse dynamics plus PI control, model reference adaptive control with velocity measurement, observer based robust adaptive control, virtual decomposition control, inverse dynamics, etc. Using Lagrangian dynamics they show the computational burden of calculating the robot dynamics increases as . [8]
Boaventura et al. used a feedback linearization controller (inverse dynamics), with the use of a slightly modified version of the actuator dynamics equation (2) shown above, as was required for compliance control. Feedback linearization is used in conjunction with a PD position controller. The authors tuned the PD loop for a phase margin of 60 degrees for a fast, non-oscillatory response. They conclude that higher valve bandwidths are able to increase the force controller stability margins and/or the closed-loop force controller bandwidth. Both the outer impedance loop and inner torque loop were sampled at 500hz. [9]
Zhihua et al. used feedback linearization in conjunction with a sliding mode controller; they also include actuator dynamics modelling. [10]
Fochi et al. compared PID, LQR and feedback linearization with servovalves with a bandwidth of 30-40 hz. They chose a state vector composed of joint angular positions and velocities, position and velocity of both cylinder rods, solenoid currents of both valves and hydraulic forces produced by the cylinders. System ID was used to estimate flow gain, valve deadband asymmetry, etc. The valve flow gain was estimated using a sinusoidal position reference and obtaining flow as a function of cylinder velocity as measured with a linear potentiometer. Valve deadband asymmetry was assessed by measuring piston displacement in both directions and valve input voltage. Valve spool dynamics were neglected since they are faster than the leg dynamics; valve overlap was compensated for algebraically with the corresponding inverse nonlinearity. The time rate of change of the hydraulic force was related to the valve voltage, Uv, through the pressure dynamics and the valve equation listed above. Regarding this equation, they indicate that f(x) contains the effects of leakage, friction and varying capacity of the cylinder chambers, while g(x) characterizes the effects of the flow-pressure nonlinearity. The authors concluded the feedback linearization controller had by far the fastest response and was the best performing controller. [11]
Bech et al. employed the same continuity equation as others for the pressure dynamics in conjunction with the orifice equation (based on Bernoulli’s equation). The authors compared four nonlinear controllers to five linear controllers and concluded all nonlinear controllers performed much better than the best linear controller. The nonlinear controllers included a sliding mode controller, adaptive inverse dynamics controller (indirect adaptive), adaptive inverse dynamics with PI control (indirect adaptive) and model reference adaptive controller with velocity feedback (direct adaptive); the adaptive inverse dynamics and MRAC controllers performed the best. Adaptive controller parameters were determined using the nonlinear constrained optimization fmincon in the MATLAB optimization toolbox. I’m unsure of the global stability claim the authors make about the adaptive inverse dynamics controller as the parameter update law appears to be a simple gradient descent. [12]
Honegger et al. utilized a high level indirect adaptive inverse dynamics control law, with a PD position control loop and a low level force PID controller with a low pass filter. The authors discuss actuator modelling; parameter estimates are adapted via gradient descent. Again, I am unsure what stability guarantees they get as a result of using gradient descent. They discuss the potential of using a feed forward term in the PID force controller to improve tracking. The control strategy is implemented with proportional control valves (Moog DDV 633), that feature an internal valve spool position controller and have a bandwidth of approximately 25hz. The sensors are sampled at 1kHz, the dynamic model is calculated at 100hz, and parameter adaptation is occurs at 20 hz. [13]
Bonchis et al. implemented a system consisting of proportional directional control valves with a bandwidth of 6hz and a 50hz controller. The authors compared tracking and robustness of 10 different control strategies, MRAC, acceleration feedback using an experimentally identified friction model (FRID), and sliding mode controllers performed the best. Inverse dynamics apparently was not considered; no other implementation details of their controllers are given. [14]
Becker et al. model actuator dynamics and implement a sliding mode controller with a continuous approximation of the sliding surface generated by a saturation function. The authors conclude the control law is strictly passive and therefore BIBO stable. They approximate the dynamic behavior of the servo-valve with a linear first-order differential equation.
The hydraulic model is based on the commercial simulation software “hyvos 6.0” from Bosch-Rexroth. Robustness was evaluated by deviating control parameters by 20 percent. They showed that given uncertainties the output error remained within the prescribed switching surface boundary. They do not discuss implementation or sampling rates, etc. [15]
In a second paper, Fochi et al. utilize a torque controller running at 1 kHz, while an outer impedance controller runs at 200hz. Torque control is achieved via a PI actuator controller, with an outer PD position control loop and inverse dynamics torque. The servovalves used have a bandwidth of 250 hz, position and velocity feedback is achieved with 80,000 PPR incremental encoders. [16]
Peng et al. discuss hydraulic actuator mathematical modelling and PID control. [17]
In a second paper Habibi et al. discuss hydraulic actuator system modelling and use in computed torque type controllers. [18]
Koivumaki discusses hydraulic actuator modelling and virtual decomposition control. [19]
Robotic system modelling is largely referenced from [20].
Hydraulic valve coefficients and other hydraulic control esoterica can be found in [21].
Destro and De Negri discuss the use of a flow coefficient, , which is used to replace the flow gain, which is a function of orifice geometry and spool position, as the orifice geometry is not easily determined from a spec sheet. [22] This coefficient is used in the actuator derivations for the HyQ robot. [1] [3] [6]
Sohl and Bobrow designed a Lyapunov based backstepping controller for the force control of a hydraulic actuator. [23] They showed that fluid bulk modulus and valve flow parameters are important for successful control and give a method for the off-line identification of those parameters. The authors also show that friction can have a large effect on tracking accuracy. The closed loop system bandwidth in their experiments was roughly 10 Hz, which allowed them to assume that the control, u, applied to the spool valve is directly proportional to the spool position, i.e. the dynamics of the valve motor / flapper are fast enough to be neglected. They indicate that in their literature review sensors used to measure the spool valve position had only a minimal performance improvement for position tracking. Their system states of cylinder position, cylinder velocity, A chamber pressure and B chamber pressure were sampled at 500 Hz. They performed system ID with various sine sweeps and used least squares to estimate the fluid bulk modulus and hydraulic valve coefficients. The authors modeled friction effects with a simple piece wise continuous linear function dependent on piston velocity. High frequency dynamics were present in the force tracking analysis due to hydraulic line dynamics at approximately 195 Hz.
3. Proposed Control Architecture
The initial proposed control system architecture is comprised of a high level inverse dynamics and PD type position control loop which then sends torque commands to a low level inverse dynamics + PID type joint torque controller, as shown in Figure 1.
Figure 1. Proposed Control Law Block Diagram
In Figure 1, the manipulator level controls will be implemented on an embedded Linux computer with a loop rate of ~60 Hz, while the joint level controllers will be implemented on a real time controller with a loop rate of 500 Hz.
A reduced form of this cascaded control structure can be seen below in Figure 2 which helps to show the high level motion controller and the low level joint controller.
Figure 2. Reduced Nonlinear Control Block Diagram
Given the design requirement of doing a full manipulation cycle every <N> seconds or faster, we will over-spec the system to operate with high performance servo-valves with a bandwidth of in excess of 200 Hz. After initial experimentation the loop rates and servo-valves may be degraded to save computation and monetary expense.
System states to be measured or estimated will be: generalized joint position, q, generalized joint velocity, , joint torque, , hydraulic cylinder position, , hydraulic cylinder velocity, , spool position, z, cylinder A chamber pressure, , cylinder B chamber pressure, , supply line pressure, , and tank pressure, .
4. Manipulator Dynamics Modeling
The dynamic model for an n-joint manipulator can readily be derived using Lagrangian mechanics and is show to be [20]:
where B is the n x n inertial matrix, C contains the effects of Coriolis and centripetal forces, F contains the effects of joint friction, is the resultant joint torque required for the motion, and is the vector of forces exerted by the environment through the manipulator Jacobian. The inertial matrix can be calculated from rotation matrices and the manipulator Jacobian. The Coriolis matrix can be calculated from the Christoffel symbols of the first type as related to the inertial matrix. Initial modelling will neglect interactions with the environment, reducing equation 4 to:
where
By setting our control input, u, to the required torque, , and introducing a virtual control input, y, we obtain:
and
This relation is the simple feedback linearization via inverse dynamics required to reduce the system to a double integrator system, which we then aim to stabilize.
By selecting a PD type controller, we obtain:
and using the relation above leads to:
As this is a simple second order system, and can be chosen as diagonal matrices of the form:
and
According to [20], given any desired trajectory, tracking of the trajectory for the output q(t) is ensured by choosing:
Finally, this yields the error dynamics:
This formulation varies slightly from that in [1] due to the fact that they technically used a computed torque method, which is additive, as opposed to inverse dynamics, which is multiplicative.
One item to note, is that upon grasping an object with the end effector, the effective mass and moment of inertia of the last link, in this case the end effector, will change substantially. This may have to take this into account when grasping an object.
5. Actuator Dynamics Modelling
Hydraulic actuator dynamics will be modeled as shown in [1].
For our application, we neglect the effects of hydraulic line and pump dynamics as most papers have done, allowing us to arrive at equation 16, governing the rate of change of generated actuator force.
where is the hydraulic cylinder position, and P is the vector of hydraulic pressures. The input u is effectively the spool position, or more specifically, the ratio of spool position to nominal spool position as indicated in [6].
By taking into account the continuity equations for the A and B side chambers of the hydraulic cylinder we obtain [1]:
and
Where is the supply pressure, is the A side chamber pressure, is the B side chamber pressure, is the tank (return) pressure, is the is the hydraulic cylinder position, is the A chamber volume as a function of cylinder position, is the B chamber volume as a function of cylinder position, is the effective bulk modulus of the hydraulic fluid, and is the valve gain defined by:
Where is the valve flow rate at the nominal input signal ( @ ), and measured at a specified pressure drop, . [22]
Note that the derivation beginning with the equations presented in [6] varies slightly from that presented in [1] due to not using the ratio of A and B side cylinder surface areas and using the quantities directly.
In light of equation 16, a feedback linearization technique can be applied to improve the force, and consequently the position tracking. By choosing a valve command u of the form:
a control law, v, can be designed to satisfy the force dynamics system requirements. The control law v was chosen as a PID type controller in [6].
By rewriting the force dynamics equation in a simplified form:
and choosing the control law, u, as we have above
our actuator force dynamics reduce to:
It is worth noting that [23], [11], [1], [3], [6] all appear to assume that the control input voltage applied to the spool valve is directly proportional to the spool position. [23] and [11] make this explicit, whereas [6] leaves the control input as a ratio of spool position to nominal spool position.
The time rate of change of hydraulic force can be related to joint torque by:
and
where r is the lever arm attached to the linear hydraulic actuator used to create a moment. [11]
In addition to these fluid power terms, there will necessarily be a term, as alluded to above, that will take into consideration the nonlinearly changing lever arm that the piston acts through.
6. Potential Avenues of Control Improvement
Perform system identification on dynamic model parameters to increase model fidelity.
Robustify the outer control loop via Lyapunov Redesign. I prefer this approach to adaptive control methods as it will likely be more robust to sudden system changes.
Make the outer control loop directly or indirectly adaptive.
If the change in the mass and moment of inertia of the end effector is causing an issue when picking up an object, a gain scheduled type of approach may need to be used wherein an approximate mass and MOI are added to the end effector link upon picking up the object.
In the 2010 paper regarding control of the HyQ robot leg, the authors indicated that since the term in the joint level inverse dynamics controller is strongly time varying it produced oscillations due to a non-ideal cancellation of the hydraulic actuator nonlinearities. The authors circumvented this by implementing a modified control law that generated a feedforward action that was applied additively to the control action v. [11] In other words, instead of using
they used:
This implementation of the control law was shown to achieve very good position tracking. In 2010 they use valve voltage as u, in the derivation of the valve pressure dynamics they use, z/zn as the control input.
7. Simulation
Simulation was performed in matlab with appropriately modeled hydraulic actuators using simulink and simscape on a 4 DoF arm.
In order to compare the usefulness of an advanced control law design, first a standard PD controller was designed without regard of the system dynamics. The simulated linear controller step response is shown below in Figure 3.
Figure 3. PD Step Response
As you can easily see in Figure 3 above, the dynamics of the system are coupled and a linear controller performs extremely poorly. If we instead synthesize a simple computed torque controller, we arrive at a step response as shown in Figure 4.
Figure 4. Computed Torque Step Response
Figure 4 illustrates the dramatic difference that can be achieved with a simple computed torque control law. If we model the full system and synthesize a high level inverse dynamics + PD control law that is then sent to a low level PID type controller to control each individual joint angle, we arrive at Figure 5, below.
From figures 5 and 6 we can easily see that the inverse dynamics controller performs quite well.
To evaluate robustness, system parameters were varied by 20% and simulations were re-run. The inverse dynamics controller still performed decently, but it appeared that parameter disturbances justified using a robust control law. For this, Lyapunov redesign was used to robustify the controllers, which then allowed them to handle parameter uncertainty up to 20% quite well.
8. Experimental Results
Unfortunately, due to time and budgetary constraints, this project was cancelled during the implementation and experimentation phase. A physical 4 degree of freedom arm was constructed, equipped with hydraulic actuators and encoders, with a System 76 laptop running Ubuntu 18.04 acting as the high level controller, which was then connected to a real time controller via an ethernet connection sending UDP messages. High and low level control software was written in C++. The real time controller was partially managed by a contract engineering firm, which proved to be too black box for our use case, and resulted in the dragging out of the project beyond initial time estimates, and ultimately, its cancellation.
9. Conclusions
A nonlinear inverse dynamics controller was synthesized for a custom 4 degree of freedom robotic manipulator and simulated. Simulations indicated that linear controllers for our highly coupled dynamics performed very poorly, whereas computed torque, inverse dynamics + PD, and inverse dynamics + PD with Lyapunov redesign performed very well.
References
[1] T. Boaventura, C. Semini, J. Buchli, M. Frigerio, M. Focchi, and D. G. Caldwell. Dynamic torque control of a hydraulic quadruped robot. In 2012 IEEE International Conference on Robotics and Automation, pages 1889–1894, May 2012.
[2] S. Feng, X. Xinjilefu, C. G. Atkeson, and J. Kim. Optimization based controller design and implementation for the atlas robot in the darpa robotics challenge finals. In 2015 IEEE-RAS 15th International Conference on Humanoid Robots (Humanoids), pages 1028–1035, Nov 2015.
[3] C. Semini. HyQ – Design and Development of a Hydraulically Actuated Quadruped Robot. PhD thesis, Italian Institute of Technology, 2010.
[4] S. Schaal. The SL Simulation and Real-Time Control Software Package. Computational Learning and Motor Control Laboratory, University of Southern California, 2006.
[5] M. R. Sirouspour and S. E. Salcudean. Nonlinear control of hydraulic robots. IEEE Transactions on Robotics and Automation, 17(2):173–182, April 2001.
[6] Thiago Cunha, Boaventura@emc Br, Claudio Semini, Darwin Caldwell, and Darwin It. Gain scheduling control for the hydraulic actuation of the hyq robot leg. 01 2009.
[7] R. J. Richards S.R. Habibi. Computed-torque and variable-structure multi-variable control of a hydraulic industrial robot. IMechE, 1991.
[8] J. Mattila, J. Koivumki, D. G. Caldwell, and C. Semini. A survey on control of hydraulic robotic manipulators with projection to future trends. IEEE/ASME Transactions on Mechatronics, 22(2):669–680, April 2017.
[9] T. Boaventura, J. Buchli, C. Semini, and D. G. Caldwell. Model-based hydraulic impedance control for dynamic robots. IEEE Transactions on Robotics, 31(6):1324–1336, Dec 2015.
[10] C. Zhihua, W. Shoukun, X. Kang, W. Junzheng, Z. Jiangbo, and N. Shanshuai. Research on high precision control of joint position servo system for hydraulic quadruped robot. In 2019 Chinese Control Conference (CCC), pages 755–760, July 2019.
[11] M. Focchi, E. Guglielmino, C. Semini, T. Boaventura, Y. Yang, and D. G. Caldwell. Control of a hydraulically-actuated quadruped robot leg. In 2010 IEEE International Conference on Robotics and Automation, pages 4182–4188, May 2010.
[12] M. M. Bech, T. O. Andersen, H. C. Pedersen, and L. Schmidt. Experimental evaluation of control strategies for hydraulic servo robot. In 2013 IEEE International Conference on Mechatronics and Automation, pages 342–347, Aug 2013.
[13] M. Honegger and P. Corke. Model-based control of hydraulically actuated manipulators. In Proceedings 2001 ICRA. IEEE International Conference on Robotics and Automation (Cat. No.01CH37164), volume 3, pages 2553–2559 vol.3, May 2001.
[14] A. Bonchis, P. I. Corke, and D. C. Rye. Experimental evaluation of position control methods for hydraulic systems. IEEE Transactions on Control Systems Technology, 10(6):876–882, Nov 2002.
[15] O. Becker, I. Pietsch, and J. Hesselbach. Robust task-space control of hydraulic robots. In 2003 IEEE International Conference on Robotics and Automation (Cat. No.03CH37422), volume 3, pages 4360–4365 vol.3, Sep. 2003.
[16] M. Focchi, T. Boaventura, C. Semini, M. Frigerio, J. Buchli, and D. G. Caldwell. Torque control based compliant actuation of a quadruped robot. In 2012 12th IEEE International Workshop on Advanced Motion Control (AMC), pages 1–6, March 2012.
[17] S. Peng, D. Branson, E. Guglielmino, and D. G. Caldwell. Simulated performance assessment of different digital hydraulic configurations for use on the hyq leg. In 2012 IEEE International Conference on Robotics and Biomimetics (ROBIO), pages 36–41, Dec 2012.
[18] S. R. Habibi, R. J. Richards, and A. A. Goldenberg. Hydraulic actuator analysis for industrial robot multivariable control. In Proceedings of 1994 American Control Conference – ACC ’94, volume 1, pages 1003–1007 vol.1, June 1994.
[19] J. Koivumaki. Virtual decomposition control of a hydraulic manipulator. Master’s thesis, Tampere University of Technology, 2012.
[20] Robotics: Modelling, Planning and Control. Springer, 2009.
[21] Noah D. Manring. Hydraulic Control Systems. Wiley, 2005.
[22] Mario C. Destro and Victor J. De Negri. Method of combining valves with symmetric and asymmetric cylinders for hydraulic systems. International Journal of Fluid Power, 19(3):126–139, 2018.
[23] G. A. Sohl and J. E. Bobrow. Experiments and simulations on the nonlinear control of a hydraulic servosystem. IEEE Transactions on Control Systems Technology, 7(2):238–247, March 1999.
My knowledge of this topic mostly comes from interview prepping with an autonomous car research lab that I ultimately passed over, though I wish I was involved with the research itself.
I’ll start with the vehicle dynamics involved, phase portrait analysis of the nonlinear system, and then talk a little bit about control methodologies.
Vehicle Dynamics
The simplest vehicle model that is widely employed with autonomous vehicles is the well known bicycle model, as this captures the majority of the dynamics that are relevant to vehicles that do not exhibit large pitch and roll dynamics.
The traditional two state bicycle model consists of the dynamic equations for the sideslip angle, , which is the ratio of the lateral to longitudinal velocities, and the yaw rate, r, with system inputs of longitudinal rear tire force, and steering angle, .
Figure 1. Two State Bicycle Model
In order to relate the front tire lateral force, to the steering angle, , we need to employ a tire model that establishes a mapping between these two quantities. In the literature from Chris Gerdes lab at Stanford, this model is typically a modified Fiala Tire Brush model.
and
By adding an additional state of lateral velocity, and augmenting the tire model to account for longitudinal force by using the well known friction circle relationship, we are able to derive the modified three state bicycle model that is used with autonomous drifting.
Figure 2. Three State Bicycle Model
Now, we come across a pretty enlightening thing when we look at two dimensional cross sections of this dynamical system as a phase portrait of r vs .
Lets look at the nominal case of a 0 degree steering angle () and a fixed velocity of 8 m/s.
Figure 3. Phase portrait of yaw rate vs sideslip angle for 0 degree steering angle
What the above phase portrait tells us is that we have a stable equilibrium point at the origin and two unstable equilibrium points at (-12.5, 0.6) and (12.5, -0.6). Intuitively, this makes sense, as the node at the origin is the case where we are driving in a straight line: the vehicle is not yawing and there is no sideslip. It is easily seen that the equilibrium point at the origin is a stable node due to all nearby trajectories being attracted to it. The two remaining equilibrium points are unstable saddle points corresponding to a left handed drift when the sideslip is negative and a right handed drift when the sideslip angle is positive. In both of these cases, the objective of control law design for a drifting autonomous ground vehicle is evident: it is to stabilize the unstable saddle points.
Let’s proceeding by sectioning the three state system at different steering angles: this time, let’s look at a steering angle of
Figure 4. Phase portrait of yaw rate vs sideslip for a steering angle of -5 degrees.
In figure 3, we see that as the steering angle is changed, so too is the position of the equilibrium points. The stable node is shifted downwards, as this coincides with a steady state right hand turn, while the two unstable saddle points shift to the left. This shifting of equilibrium points indicates that our region of attraction in the third quadrant is getting much smaller; this is due to the front tires getting closer and closer to the friction limit.
When we continue to increase our steering angle we see what is one thing that makes nonlinear systems so tricky: a bifurcation. At this steering angle, the stable node and the unstable saddle point collide and annihilate each other, leaving a sole unstable equilibrium point. This bifurcation effectively illustrates the case when the steering angle is increased until the front tires become friction limited and break lose, causing the vehicle to spin out.
Figure 5. Saddle Node Bifurcation
Controller Design
Now, as I stated above, I wasn’t involved in any of this research, and therefore have not implemented any of these controllers, but I can attest to the model derivations, as I’m intimately familiar with them.
Now then, let’s get down to business (to defeat, the huns!)
Voser, Hindiyeh and Gerdes used a cascaded longitudinal controller and steering controller architecture around a reference steering angle of -15 degrees.
The longitudinal control law is a simple SISO proportional controller:
The steering control law is a two state, state space representation of the linearized bicycle model about the desired drift equilibrium . The choice of feeding back the longitudinal velocity is done in order to decouple the steering and longitudinal controllers, as selecting the sideslip angle, would keep these dynamics coupled.
With this in mind the steering controller is designed as:
Putting this in state space form we obtain:
Where the state vector is and the control input scalar is .
Upon defining the gain matrix K as , it is easily shown that closed-loop stability of the system is achieved when the eigenvalues of A – BK have negative real part (remember back to your linear systems class where the closed loop state space representation is ). With this in mind, the stable gain subspace is defined by equation 7, which will come in an upcoming update : ) .
In the last project we showed, by using python and tensorflow, that we can create a ConvNet to classify traffic signs with a relatively low error rate. What if we want to do something a little more complex, though? Say, something like replicate behaviors that a system should take given a set of inputs.
This is just the problem posed to students with the 3rd project in term 1 of the self driving car engineer nano degree series.
Regression vs Classification
In order to replicate a behavior, we are dealing with a regression problem, which is unlike our previous problem of classification. The main difference being that we are no longer concerned with our network outputs corresponding to a probability that something belongs to a class, in such case it is predicting a discrete class label, but rather, they predict a continuous quantity, such as throttle and steering angles.
If you read the previous post, you will remember that we used a softmax cross-entropy function to convert the outputs of our last layer to probabilities of something belonging to each of our classes. Instead, we will use a mean squared error function for our loss layer, which is then again fed into an adam optimizer.
Project Problem Statement
The goals of this project are the following:
Use the provided simulator to collect data of good driving behavior. This includes steering angle, camera imagery, throttle position and brake pressure.
Build a convolutional neural network in Keras that predicts steering angles from images.
Train and validate the model with a training and validation set.
Test that the model successfully drives around the track without leaving the road.
Write up and Results
The model constructed is basically the same as the Nvidia model shown below, with the exception of added dropout layers.
The model used includes ReLU activation layers to introduce nonlinearity, and the data is normalized using Keras’ lambda layer. Additionally, cropping was performed to help normalize images.
Attempts were made to use ELU activation functions, but those proved harder to train and performed worse than when using ReLUs.
In order to prevent overfitting dropout layers were incorporated. Additionally, the model was trained and validated on different data sets to prevent overfitting.
The model was trained using an Adam optimizer with a learning rate of 0.0001.
Training data was chosen that I thought would give the best probability of keeping the vehicle on the road. I used a combination of center lane driving, recovering from left and right side departures from the road, driving around a second track, and spending additional time connecting data from very sharp, “extreme” turns.
After collection of training data I wrote a python sript to normalize the distribution of angles that are fed into the training script. I divided the range of [-1.0 rad, 1.0 rad] into 21 bins and thresholded the number allowed in these bins to 1000. After a lot of data recording the training data distribution appeared as follows:
As is the case with many machine learning problems using neural networks, my goal was to use a previously existing model architecture and re-train it for my application.
My first handful of attempts at training a model indicated that overfitting was occurring as the training set showed a low mean squared error, but the validation MSE was quite high. To combat this I used dropout layers as indicated above.
After final construction of the model and testing with my own data set, the CNN still showed it was having a difficult time keeping the car on track. As with most neural network tasks, it seems that the distribution of the data set is more important than the actual format of the network. I therefore created a script to bin the steering angles into 21 bins and threshold the acceptable number of items in each bin to 1000. After quite a bit of data collection and binning I was able to have 21 bins of nearly 1000 items each, which produced a relatively flat distribution. With this new data set of nearly uniform distribution the trained model seemed to perform quite well and kept the car on track.
The mean squared error loss during training can be seen below:
The second project in the computer vision oriented term 1 tasks the student to train a classifier to correctly classify signs using a convolutional neural network constructed in python using TensorFlow. My full github repo for the project is located here.
The primary CNN model used to solve this classification problem is a modified LeNet architecture with the addition of dropout layers between fully connected layers to prevent overfitting.
CNN Architecture
The standard LeNet-5 architecture is shown below, which is retrieved from the original paper.
LeNet-5 Architecture
The final architecture used is summarized below:
Layer
Description
Input
32x32x3 RGB image
Convolution 5×5
1×1 stride, valid padding, outputs 28x28x6
RELU
Max pooling
2×2 stride, outputs 14x14x6
Convolution 5×5
1×1 stride, valid padding, outputs 10x10x16
RELU
Max pooling
2×2 stride, outputs 5x5x16
Fully connected
400 inputs, 120 outputs
RELU
Dropout
Keep prob = 0.5
Fully connected
120 inputs, 84 outputs
RELU
Dropout
Keep prob = 0.5
Fully Connected
84 inputs, 43 outputs
Softmax
CNN Building Blocks
Neurons
As with standard neural networks, at the core of the convolutional neural network are still neurons, connected by synapses, which compute a dot product of inputs and weights, add to it a bias, pass this to an activation function, and then output this to the next layer.
As you may expect, the convolutional layer is the core building block of convolutional neural networks. The convolutional layer consists of a set of learnable filters, or kernels, that are convolved with the input, in this case a 3 channel image.
During the forward pass, each kernel (there may be more than one), is convolved spatially across the input image, thereby creating a 2-dimensional activation map of that kernel. This results in the network learning a kernel (filter) that will activate when it detects a specific type of feature at a certain spatial position in the input image.
Local Connectivity
Due to the high dimensionality of images, if we were to connect every neuron in one volume to everyone neuron in the next, we would have an almost crazy number of parameters, which would result in a very high computational expense. CNNs therefore depend on the concept of local connectivity, and receptive field. The receptive field, to put it simply, is the size of the kernel used in convolution, which results in only local spatial connections between layers.
Activation Functions
Rectified linear units, or ReLUs, were used as activation functions for the traffic sign classifier CNN. When selecting an activation function, the designer should note that only nonlinear activation functions allow neural networks to compute nontrivial problems using only a small number of nodes. In fact, when a nonlinear activation function is used, then a two-layer neural network can be proven to be a universal function approximator.
Exponential Linear Unit (ELU)
Rectified Linear Unit (ReLU)
Hyperbolic Tangent Function
Logistic Sigmoid
Softmax
The softmax is used in the last fully connected layer to be able to convert outputs from the previous layer into probabilities for each output class. Mathematically, it may be defined as follows:
The ReLU is often preferred to other nonlinear activation functions because it trains the neural network several times faster without a significant penalty to the generalization accuracy.
Alternative nonlinear activation functions that are sometimes used include the hyperbolic tangent function, the exponential linear unit, and the logistic sigmoid function. The ELU is a function that tends to converge cost to zero fast and produce accurate results. The ELU is very similar to the ReLU, except that negative inputs result in a non-zero activation that smoothly becomes equal to .
Pooling Layers
Pooling layers act to non-linearly downsample the input image. This is necessary because, at their core, neural networks act to reduce the dimensionality of their inputs; for classification afterall, we need to go from an input image of mxn pixels, with a depth of 3, into a certain class, which is a single output. In other words, pooling layers combine the outputs of neuron clusters in the previous layer into a single neuron input in the next layer.
Max pooling is one of the more common types of pooling functions used. In essence, they downsample by extracting the maximum value in a certain filter space. The image below, taken from wikipedia, illustrates how this is performed for a max pooling filter of dimensionality 2×2 and stride of 2.
Fully Connected Layers
Like the name suggests, fully connected layers connect every neuron in one layer to every neuron in the next layer. Fully connected layers typically appear at the end of a network and serve as the final, high-level reasoning device within CNNs.
The output from the convolutional, pooling, and other layers in a CNN represent high-level features of an input image. It is the job of the fully connected layer to use these features to classify the input image into the appropriate classes based on the training data.
Loss Layers
I mentioned the softmax function above, which is one example of a loss function used in loss layers.
In the traffic sign classifier problem I utilized a softmax cross entropy loss function as the loss operation to be minimized.
Utilizing Dropout to Prevent Overfitting
Dropout is simply a regularization technique that aims to prevent overfitting by randomly, or otherwise, dropping out units in a neural network.
Writeup and Results
The student is provided pickled data that contains a dictionary with 4 key/value pairs:
'features' is a 4D array containing raw pixel data of the traffic sign images, (num examples, width, height, channels).
'labels' is a 1D array containing the label/class id of the traffic sign. The file signnames.csv contains id -> name mappings for each id.
'sizes' is a list containing tuples, (width, height) representing the original width and height the image.
'coords' is a list containing tuples, (x1, y1, x2, y2) representing coordinates of a bounding box around the sign in the image. THESE COORDINATES ASSUME THE ORIGINAL IMAGE. THE PICKLED DATA CONTAINS RESIZED VERSIONS (32 by 32) OF THESE IMAGES
To train the model, I used a learning rate of 0.001, 100 epochs, although I could have used far less, and a batch size of 128. I chose to use the Adam optimizer because from the papers I’ve read adaptive optimizers appeared to have the best performance and were the least computationally expensive.
My final model results were:
training set accuracy of 0.998
validation set accuracy of 0.954
test set accuracy of 0.939
f an iterative approach was chosen:
What was the first architecture that was tried and why was it chosen?
I first chose the basic LeNet architecture.
What were some problems with the initial architecture?
The initial training sets were achieving training accuracies of nearly 1.000 while the validation accuracy was only around 0.870. This indicated that the model wasn’t able to generalize what it learned in the training set to the validation set well.
How was the architecture adjusted and why was it adjusted? Typical adjustments could include choosing a different model architecture, adding or taking away layers (pooling, dropout, convolution, etc), using an activation function or changing the activation function. One common justification for adjusting an architecture would be due to over fitting or under fitting. A high accuracy on the training set but low accuracy on the validation set indicates over fitting; a low accuracy on both sets indicates under fitting.
I moved on to try adding layers of convolutions as well as in the fully connected classifier layer. I then moved on to try some inception modules. From there improved the training data set and added dropout because the training set was achieving very good accuracies whereas the validation set was still achieving relatively poor performance.
Which parameters were tuned? How were they adjusted and why?
I played with the learning rate a bit but decided to leave it at 0.001. I increased the number of epochs based on where I saw the optimizer begin to stall.
What are some of the important design choices and why were they chosen? For example, why might a convolution layer work well with this problem? How might a dropout layer help with creating a successful model?
I think the dropout layers helped because it allowed the model to have backup methods of classification which further allowed the model to generalize to the validation set.
Here is an exploratory visualization of the data set. It is a bar chart showing how the training samples are distributed.
Number of training examples = 34799
Number of testing examples = 12630
Number of validation examples = 4410
Image data shape = (32, 32, 3)
From the histogram we can see there are 43 classses
One thing you’ll notice about the training data set is that some classes are over-represented as compared to others. With this observation I opted to generate additional data to ensure that the distribution was more even. To add more data to the the data set, I translated images, rotated them and applied an affine transformation to shear them.
My final training set had 146574 images (after modified images being added). My validation set and test set had 4410 and 12630 images. These last two numbers were unaltered because they were given to us as separate pickles. Interestingly when I used train_test_split to generate validation images instead of using the ones given to us I achieved higher validation rates, which makes me question the validation image set that was given to us.
Here are some examples of modified images that were added to the data set:
And here is the histogram of how many images there are after processing for each class:
Here is a random sampling of data from the set of non-processed and processed imagery fed to the network for training:
schikit learn was used to shuffle the data, and tensorflow was used as the primary machine learning library.
# train
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
num_examples = len(X_train)
print("Training...")
print()
for i in range(EPOCHS):
X_train, y_train = shuffle(X_train, y_train)
for offset in range(0, num_examples, BATCH_SIZE):
end = offset + BATCH_SIZE
batch_x, batch_y = X_train[offset:end], y_train[offset:end]
sess.run(training_operation, feed_dict={x: batch_x, y: batch_y, keep_prob: 0.5})
training_accuracy = evaluate(X_train,y_train)
validation_accuracy = evaluate(X_validation, y_validation)
print("EPOCH {} ...".format(i+1))
print("Training Accuracy = {:.3f}".format(training_accuracy))
print("Validation Accuracy = {:.3f}".format(validation_accuracy))
print()
saver.save(sess, 'model')
print("Model saved")
A validation set can be used to assess how well the model is performing, which I mentioned I used scikit learn to split up for me previously. The first ten epochs of training resulted in the following training and validation accuracies:
As we can see, the training and validation accuracies are still increasing, meaning beneficial learning is occurring. If we notice, however, that the validation accuracy begins to drop, it is evident that overfitting is occurring and the model is not able to generalize beyond its training data set.





















 is the fluid density, t is time, and u is the flow velocity vector field.
is the fluid density, t is time, and u is the flow velocity vector field.
 , the cylinder A side chamber pressure, Pa, cylinder B side chamber pressure, Pb, the supply pressure, Ps, the tank pressure Pt, and torque,
, the cylinder A side chamber pressure, Pa, cylinder B side chamber pressure, Pb, the supply pressure, Ps, the tank pressure Pt, and torque,  . The position control law uses only position feedback. The inverse dynamics term is governed by a reference angular acceleration (reference trajectory shaping), and feedback angular position and angular velocity. The largest control effort is exerted by the inverse dynamics term.
. The position control law uses only position feedback. The inverse dynamics term is governed by a reference angular acceleration (reference trajectory shaping), and feedback angular position and angular velocity. The largest control effort is exerted by the inverse dynamics term. and
and  for the actuator dynamics are included in an appendix, where the A and B pressures, and valve spool position are used as states. [5]
for the actuator dynamics are included in an appendix, where the A and B pressures, and valve spool position are used as states. [5] . [8]
. [8]
 , which is used to replace the flow gain, which is a function of orifice geometry and spool position, as the orifice geometry is not easily determined from a spec sheet. [22] This coefficient is used in the actuator derivations for the HyQ robot. [1] [3] [6]
, which is used to replace the flow gain, which is a function of orifice geometry and spool position, as the orifice geometry is not easily determined from a spec sheet. [22] This coefficient is used in the actuator derivations for the HyQ robot. [1] [3] [6]

 , joint torque,
, joint torque,  , hydraulic cylinder velocity,
, hydraulic cylinder velocity,  , spool position, z, cylinder A chamber pressure,
, spool position, z, cylinder A chamber pressure,  , cylinder B chamber pressure,
, cylinder B chamber pressure,  , supply line pressure,
, supply line pressure,  , and tank pressure,
, and tank pressure,  .
.
 is the vector of forces exerted by the environment through the manipulator Jacobian. The inertial matrix can be calculated from rotation matrices and the manipulator Jacobian. The Coriolis matrix can be calculated from the Christoffel symbols of the first type as related to the inertial matrix. Initial modelling will neglect interactions with the environment, reducing equation 4 to:
is the vector of forces exerted by the environment through the manipulator Jacobian. The inertial matrix can be calculated from rotation matrices and the manipulator Jacobian. The Coriolis matrix can be calculated from the Christoffel symbols of the first type as related to the inertial matrix. Initial modelling will neglect interactions with the environment, reducing equation 4 to:

 , and introducing a virtual control input, y, we obtain:
, and introducing a virtual control input, y, we obtain:




 and
and  can be chosen as diagonal matrices of the form:
can be chosen as diagonal matrices of the form:




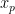 is the hydraulic cylinder position, and P is the vector of hydraulic pressures. The input u is effectively the spool position, or more specifically, the ratio of spool position to nominal spool position as indicated in [6].
is the hydraulic cylinder position, and P is the vector of hydraulic pressures. The input u is effectively the spool position, or more specifically, the ratio of spool position to nominal spool position as indicated in [6].

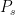 is the supply pressure,
is the supply pressure,  is the A side chamber pressure,
is the A side chamber pressure,  is the B side chamber pressure,
is the B side chamber pressure,  is the tank (return) pressure,
is the tank (return) pressure,  is the A chamber volume as a function of cylinder position,
is the A chamber volume as a function of cylinder position,  is the B chamber volume as a function of cylinder position,
is the B chamber volume as a function of cylinder position,  is the effective bulk modulus of the hydraulic fluid, and
is the effective bulk modulus of the hydraulic fluid, and 
 is the valve flow rate at the nominal input signal (
is the valve flow rate at the nominal input signal ( ), and measured at a specified pressure drop,
), and measured at a specified pressure drop,  . [22]
. [22]






 term in the joint level inverse dynamics controller is strongly time varying it produced oscillations due to a non-ideal cancellation of the hydraulic actuator nonlinearities. The authors circumvented this by implementing a modified control law that generated a feedforward action
term in the joint level inverse dynamics controller is strongly time varying it produced oscillations due to a non-ideal cancellation of the hydraulic actuator nonlinearities. The authors circumvented this by implementing a modified control law that generated a feedforward action  that was applied additively to the control action v. [11] In other words, instead of using
that was applied additively to the control action v. [11] In other words, instead of using





 and steering angle,
and steering angle, 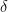 .
.
 to the steering angle,
to the steering angle, 



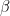 .
. ) and a fixed velocity of 8 m/s.
) and a fixed velocity of 8 m/s.




 . The choice of feeding back the longitudinal velocity is done in order to decouple the steering and longitudinal controllers, as selecting the sideslip angle,
. The choice of feeding back the longitudinal velocity is done in order to decouple the steering and longitudinal controllers, as selecting the sideslip angle, 

![x = \left [ \Delta v_y, \Delta r \right]^T](https://s0.wp.com/latex.php?latex=x+%3D+%5Cleft+%5B+%5CDelta+v_y%2C+%5CDelta+r+%5Cright%5D%5ET&bg=ffffff&fg=000&s=0&c=20201002) and the control input scalar is
and the control input scalar is  .
.![K = \left [ K_{vy}, K_r \right ]](https://s0.wp.com/latex.php?latex=K+%3D+%5Cleft+%5B+K_%7Bvy%7D%2C+K_r+%5Cright+%5D&bg=ffffff&fg=000&s=0&c=20201002) , it is easily shown that closed-loop stability of the system is achieved when the eigenvalues of A – BK have negative real part (remember back to your linear systems class where the closed loop state space representation is
, it is easily shown that closed-loop stability of the system is achieved when the eigenvalues of A – BK have negative real part (remember back to your linear systems class where the closed loop state space representation is  ). With this in mind, the stable gain subspace is defined by equation 7, which will come in an upcoming update : ) .
). With this in mind, the stable gain subspace is defined by equation 7, which will come in an upcoming update : ) .














 .
.



