The Udacity SDC Engineer Nanodegree Term 1 begins with using basic computer vision algorithms to detect lane lines from a video and display them on screen.
Problem Statement
In this project, you will use the tools you learned about in the lesson to identify lane lines on the road. Once you have a result that looks roughly like “raw-lines-example.mp4”, you’ll need to get creative and try to average and/or extrapolate the line segments you’ve detected to map out the full extent of the lane lines. You can see an example of the result you’re going for in the video “P1_example.mp4”. Ultimately, you would like to draw just one line for the left side of the lane, and one for the right.
The tools you have are color selection, region of interest selection, grayscaling, Gaussian smoothing, Canny Edge Detection and Hough Tranform line detection. You are also free to explore and try other techniques that were not presented in the lesson. Your goal is piece together a pipeline to detect the line segments in the image, then average/extrapolate them and draw them onto the image for display (as below).
Solution and Write up
I will copy and paste sections from the iPython notebook that I made for this project. The Full project can be found on my github.
1. Describe your pipeline.
My lane line detection pipeline consists of the following steps:
Convert each video frame to grayscale.
Threshold the grayscale image.
Apply region of interest to where lane lines are expected to be.
Perform Canny edge detected (dilated here for easier viewing).
5. Perform the Hough transform (here with lines drawn).
6. Extend hough transform lines and bin them by positive and negative slopes: Extending is done by taking the two tuples (x1,y1), (x2,y2) output from houghLinesP(), determining the slope for each line, and then determining a leftmost and rightmost point across the image to draw a line between.
7. Determine if both lane lines are detected, if one is not, draw one that is offset from the other lane line by a nominal amount so it is a function of the detected line. 8. If both lane lines are detected, perform least squares fit on positive and negative sloped lines:
9. Draw these least squares fit lines on an empty array and perform region of interest trimming to get rid of line segments extending beyond the horizon. 10. Overlay these lane lines on the original image and display them:
2. Identify potential shortcomings with your current pipeline
Potential shortcomings arise from situations where lane lines do not have high contrast with their background, when lines are occluded, or they are shadowed. For these situations there is no recovery behavior and vision can only be of so much assistance.
Another shortcoming is that if lane lines become too misaligned from the slopes expected they will not be registered as lane lines due to the binning process I, have which sorts things by their determined slope.
3. Suggest possible improvements to your pipeline
One large improvement would be to low pass or kalman filter the positions and slopes of the lane lines so that they are not memoryless like they currently are. This would dampen (add inertia) to the system and cause the lines to jitter much less.
Another potential improvement could be to filter the color image according to an RGB mask, as opposed to my simple grayscale threshold.
A further improvement would be to monitor the residual error terms or the covariance of the least squares line fitting to determine how much certainty there is in the fit. This could be used to monitor the state of the detection algorithm, and if the covariance becomes large some kind of recovery behavior within the code could be triggered.
A while back when I was working on tuning the control loops for the expressive degrees of freedom of our robot I thought I’d make a video showing a more fun example of classical controls tuning when you don’t know your system than what I typically see in classrooms.
For this, I’m using a DC motor as an actuator, hall effect quadrature encoder for position sensing, ROS with rqt_plot to visualize the position input and output, dynamic reconfigure to change the control gains, and have a few python scripts to generate and publish reference trajectories.
Step Response
I begin by just publishing a reference step function between 0 and 600 encoder ticks and start twiddling control gains! I’m doing this as quickly as I can to illustrate that you can tune things without actually looking at time domain step response parameters like rise time, settling time, etc.
PID Tuning Via Step Response
Note: at 3:27 I mispoke and say “proportional term” when I actually meant “integral term”.
Frequency Response
After first tuning my gains via visual inspection from a step response, I move on to a frequency response to illustrate what tracking of a varying frequency sinusoidal position input looks like.
The basic thing that I’m trying to convey to students is that the rise time and overshoot from our step response can in a way be translated to our frequency response. When the inverse of the frequency is faster than our rise time, we begin to see that the magnitude of our frequency response decreases. When the inverse of the frequency is at about the time that we see an overshoot in step response we begin to see the beginning of a resonant peak in our frequency response.
Frequency Response
Putting It All Together
I’m just kidding, this is me goofing off, but system dynamics and controls don’t need be dry and boring! Ignore the commentary, we were delirious from working long hours.
While working in Silicon Valley, I quickly learned how valuable it is to, well, move quickly. One of the easiest ways to do this when dealing with real-world, tangible things, is to be able to quickly mock up and prototype ideas: whether it’s a sensor fixture, calibration device, mobile robot base, etc, chances are if you modify the way you think about design a little bit you can make it almost entirely out of laser cut and 3D printed parts. Before we get into things, I need to thank Josh Vasquez, who has been a contributing writer at Hackaday for a while now, for getting my feet wet with all this laser cutting nonsense and sharing just a little bit of his ridiculously vast maker knowledge with me. Now, with this great and unmatched introduction complete(note: LOL), let’s dig in!
Why Laser Cutting?
Well, from my experience, laser cutting is likely going to be the fastest, simplest method of creating planar parts with complex geometries. In fact, if you’re able to think about designing things a little bit differently, you can make pretty complex three-dimensional things with laser cutters, from this prototype robot mobile base, to this objectively crazy tentacle arm Josh made.
Kuri Tank Drive Prototype
Josh’s Two Stage Tentacle Mechanism
In fact, the dimensional repeatability and precision afforded by laser cutters means you can make calibration and characterization rigs for sensors in a matter of minutes, from this rig I made to create a sensor model for the ST VL6180x time of flight proximity sensor, to this fiber optic calibration board for a time of flight camera.
VL6180x Characterization Rig
Calibration Board Front
Calibration Board Rear
Calibration Board Detection
Benefits of Laser Cutting to Your Business
Now, if you’re trying to sell something like purchasing a laser cutter, or even 3D printer, to your boss at a big company, it’s pretty easy to make a business justification.
Speed
Laser cutting allows for greatly reduced iteration time on designs.
Cost
Huge employee time savings translate to money savings.
Results in less wasted material than conventional machining.
Design Quality
Better quality than conventional machining is achieved in much less time.
Laser Cutters to Purchase
For most professional environments that require a laser cutter for quick prototyping, think startups and research labs, I usually recommend something like the 75 Watt Universal Laser Systems PLS6.75. At the time of writing this, a system like this will cost about $30,000.00, not including the PC used for the control software, the compressor used to forcibly provide airflow, I recommend this one, and whatever ventilation system you use.
ULS PLS6.75 Laser Cutter
The PLS6.75 has a nominal working area of 18″x36″x9″, but can be increased slightly by removing one of the alignment rails in the bed. In terms of cutting performance, the above machine has a nominal kerf thickness of about 0.007″, with dimensional accuracy and repeatability of less than 0.002″. If you so wish, you can purchase additional focusing optics to reduce the kerf thickness all the way down to 0.001″.
It’s good to know the kerf thickness of your laser cutter as this will dictate how much you need to offset your drawings or parts by to achieve the nominal size. For the above case of a 0.007″ kerf, for parts that require VERY precise dimensions, I will offset all of the lines by 0.003″ and call it good. If thing’s don’t need that level of precision I generally ignore offsetting things.
All ULS systems are super user friendly. They have auto-focus, auto-z-levelling, and a huge material library so all you have to do is select your material and material thickness.
What Materials Should I use?
Hint: It’s probably Delrin.
For cheaper, less structurally important things, I’ll typically see people use acrylic or plywood. When things need to stand up to a bit more abuse, or you need things like press fits, counter sunk features, the use of thread forming screws, snap fits, or even something that slides easily and is tough, I without hesitation recommend Delrin.
Why? It’s pretty simple, really: Delrin is far more ductile than acrylic and is, generally speaking, homogeneous and isotropic, whereas wood is not. Delrin requires a huge amount of strain for it to fail, both in tension and compression, whereas wood and acrylic will yield at very low strains.
What Exactly Is it?
Delrin, as the cool kids call it, is actually just a brand name like Kleenex is. More generally speaking, Acetal is the common name for an entire family of thermoplastics known as polyoxymethylene, or POM. Delrin then, which is manufactured by DuPont, refers to homopolymer acetal (POM-H), which is distinguished from copolymer acetal (POM-C).
What are the differences? Well, to someone just slapping together a mock up of something, likely not much that they would care about, and material properties are generally within 10% of each other so they can be swapped for one another.
Typically you’ll only see delrin come in its natural white color, or dyed black, though other colors are possible (just not common).
One more thing to note about delrin, as opposed to acetal copolymer, is that due to the extrusion process used, there will be built up internal stresses caused by the outside of the sheet cooling before the inside.
Sourcing Delrin Sheets
I almost always buy flat delrin sheets from OnlineMetals, as opposed to other places like McMaster-Carr, due to OM taking more care to ensure that the sheets are flat and stay flat. If you’re looking for additional sources, or require things to be cut to a particular size a good place to look is ePlastics.
Delrin Prototyping Techniques
Most of the contents of this section are credited to Josh, as he already did a similar write-up and I’m simply regurgitating them in different words.
The Press-Fit
If you look through a standard design of machinery or machining textbook, you’ll typically see that press-fit tolerances are listed as ±0.0005″. Well, we definitely can’t get those types of tolerances with middle-end laser cutters, but thanks to delrin being much more flexible, we can easily create press fits without having to worry too much about the actual tolerancing.
When using a new laser, if I need to achieve a pressfit without knowing much about it, I will simply create an array of parts with each element having a line offset by increments of 0.001″, and then see which I like the fit of the best. If you just want to wing it, a general rule is to just slightly undersize your hole as compared to a normal, machined metal, pressfit.
Countersinking
Because delrin is so easily machined, you can create countersunk holes using nothing more than a counter-sink drill bit and your hand.
Thread-Forming
Again, because delrin is so easily machined, it’s super easy to screw in thread-forming PT screws. Some people will even go far enough to just size the hole according to the tap size required for the hole if you were to tap threads, and just screw in a standard screw!
Threaded Inserts
If you want something that will stand up to a few more installations and removals than using a thread-forming screw, the go-to solution is a PEM threaded insert. Simply size your hole according to their guide, take the PEM insert and throw it on the end of a soldering iron that’s on low, and press it into the delrin. The delrin will soften and the insert will slide in like butter.
Snap-Fits
Another benefit of delrin having such a high maximum strain is that we can easily create snap fits and tabs. It’s so accommodating of strains in tension that I typically will just eyeball what I think looks “OK” and then just go with it.
Gallery of Interesting Projects
Now that I’ve talked about different techniques and all that, here’s some of what I’ve done using a 60 watt ULS CO2 laser cutter.
Permanently Marking Metals
With a little bit of CerMark LMM6000, you’re able to spray a layer of black on stainless steel, or other hard metals, and then permanently mark the material with whatever you desire. You’ll have to do a little bit of guessing in regards to the laser parameters, so you can either make one item sacrificial and etch a calibration template onto it with different laser powers, or just take a wild guess like I did with this commemorative flask I made for a group of us on a mountaineering trip:
Commemorative Stainless Steel Flask
Accompanying Laser Cutter Settings
If you want to do the same for softer metals like aluminum, just switch to CerMark LMM14.
Laser Engraved Wooden Map
A fun thing I got into as a little side hobby was to create custom laser engraved maps and signs for people. Check out this 12″x24″ map of the San Francisco Bay Area and a plaque I made for a friend’s newborn:
Engraved Map of the Bay Area on Pine
Plaque for my Friend’s Son on Birch. Quote via Stanza 15 of the Havamal
Maps like the above are actually quite a bit easier than you’d think, it really just requires writing a little bit of code to to the set up, then properly configuring everything to easily be etched by the cutter. Pro tip: when etching on wood, avoid scorch marks like you can see along the bayside shore of the peninsula by putting down a layer of masking tape. This general does a pretty good job of preventing scorching, with the remainder easily removed by sanding.
MEMS Microphone Hydrophobic Mesh and Acoustic Impedence
Even though I regularly advertise one of the strengths of laser cutters being that most jobs are a simple single-fixture operation, that doesn’t mean you can’t do multi-fixture and multi-material cuts. Take for example this hydrophobic mesh used as an acoustic impedance for the microphone array in our robot’s neck. This stackup consists of a layer of SaatiFil Acoustex 090 to both act as acoustic impedance and protect against water ingress, as well as a layer of 3M PSA. This required adhering everything to a cut delrin plate, first cutting the adhesive, as we don’t want it in the sound inlet hole, then adhering the Acoustex to it, and cutting that.
Final Patterned and Cut Mesh Stackup
Section of Robot Skin with Mesh Installed
Kuri Robot CES Prototypes
Even things like our alpha stage prototypes that won us awards at CES 2017 had laser cut pieces. Check out all of the different mounting plates and tiered platforms of our robot without the cosmetic skins on:
No, they’re not named after the three kids on my highschool football team that thought they were super cool and referred to themselves as the regulators.
Building off of what we talked about in the case of the Kalman filter, we can derive a state space regulator that is also optimal in some sense. This sense is to drive some state x to the smallest possible value as soon as possible, but without spending too much control effort to achieve that goal. Given a continuous-time linear time invariant (LTI) system of the form
The above dynamic system looks more complicated that it needs to be because we have a measured output y, and a controlled output z. The measured output is the signal that we have available for measurement, whereas the controlled output is the signal that we would like to make as small as possible in the shortest time possible. It’s possible that z and y are the same, or z can be comprised of y and it’s derivative, etc.
The LQR problem is then to find a control input, u, that minimizes the following cost function:
is simply a tuning parameter used to weigh which part of our minimization problem we want to place more importance on. Is it more important for us to minimize the energy of the controlled output, z? Then select to be very small. Is it more important for us to minimize the energy of the control signal, u? Then select to be very large. One of the things that makes the LQR a bit annoying to some is that the LQR problem involves minimizing both of these energies.
Equation 2 is useful because it illustrates more compactly what we are trying to achieve, but the LQR problem is usually written more generally in textbooks as
Where and are symmetric positive-definite matrices.
Or we can represent things in a bit more complicated way as:
Without getting into the math yet (algebraic Riccati equations, yay!) the feedback control law that minimizes the value of the above cost function is
Where the control gain, K is given by:
Where P is the solution to the, in this case, continuous time algebraic Ricatti equation (ARE):
Note: another thing I’ve noticed is that algebraic Riccati equation is a bit of a buzz word with a lot of students not being able to define what one is and profs just throwing it around like “ofcourse, if you remember back to 3rd grade, just after learning your multiplication tables you’ll recall the ever present algebraic Ricatti equation.” -_- Now, a Riccati equation is just any first-order ordinary differential equation that is quadratic in the unknown function. In our case, P is the unknown function, and if we carry out all of the matrix multiplications we can easily see that the equation in question is quadratic in P.
Now, this is about the point where people start to get frustrated with LQRs… not only do we have these stupid matrices Q and R that we have to figure out what to do with, but we also have to figure out how to solve the ARE above. Oh, and there’s now this nuisance of a cross term, N, that most books decide, in a super frustrating fashion, to just ignore talking about.
To arrive back at the more simple representation in equation 2 we use the following relations:
And to arrive back at the slightly more general equation 3, use the following relations:
If you’re using Matlab, as it seems like controls theoriticians are absolutely in love with (move to python, please), you can use the command:
[K, P, E] = lqr(A,B,Q,R,N)
to solve the ARE and compute the optimal state feedback gain matrix, K.
Now we are left with a couple things to scratch our head about.
First, what the hell do we do with those and matrices? And second, how the hell do we actually solve that algebraic Riccati equation?
The first one is a bit easier to tackle. The simplest thing to do is set . From here we just vary the single parameter until we get something that has a decent response.
Many books suggest using Bryson’s Rule to begin your tuning of the LQR [1]
which then corresponds to the following cost function
This effectively sets the maximum acceptable value for each term to be 1. This generally gives semi-decent results, but really only acts as a starting point for us to start twiddling our control engineer knobs.
For example, if for our first state we want the maximum possible error to be 1 m and the second state to have a maximum possible error of 1/60 radians, we can use the following
The second question can be easy or hard… If you just want to use an already available library, like the python control library, you can just use the lqr method of the control class.
OR, you can write your own solver piggybacking on the scipy linear algebra library using the following code snippet[2]:
import numpy as np
import scipy.linalg
def lqr(A,B,Q,R):
"""Solve the continuous time lqr controller.
dx/dt = A x + B u
cost = integral x.T*Q*x + u.T*R*u
"""
#ref Bertsekas, p.151
#first, try to solve the ricatti equation
X = np.matrix(scipy.linalg.solve_continuous_are(A, B, Q, R))
#compute the LQR gain
K = np.matrix(scipy.linalg.inv(R)*(B.T*X))
eigVals, eigVecs = scipy.linalg.eig(A-B*K)
return K, X, eigVals
def dlqr(A,B,Q,R):
"""Solve the discrete time lqr controller.
x[k+1] = A x[k] + B u[k]
cost = sum x[k].T*Q*x[k] + u[k].T*R*u[k]
"""
#ref Bertsekas, p.151
#first, try to solve the ricatti equation
X = np.matrix(scipy.linalg.solve_discrete_are(A, B, Q, R))
#compute the LQR gain
K = np.matrix(scipy.linalg.inv(B.T*X*B+R)*(B.T*X*A))
eigVals, eigVecs = scipy.linalg.eig(A-B*K)
return K, X, eigVals
If you’re interested in writing your own solver, what you can do is solve the ARE via the eigenvalues and eigenvectors of the Hamiltonian matrix.
I’ll expand on this Hamiltonian matrix solution more later, but for now I’ll leave off by saying that we first construct the Hamiltonian matrix, find the eigenvalues and eigenvectors of it, selected the eigenvectors associated with stable eigenvalues, then compute the steady state solution P from these.
References
Hespahna, J. (2009). Linear Systems Theory. Princeton University Press
What’s better than a Kalman filter? An Extended Kalman Filter! [1] (I’m just kidding, this isn’t from the book, but wouldn’t it be awesome if it was? Most of the other stuff in here is, though.)
Up until now all of our estimators have necessarily required the system dynamics to be linear and time invariant. Unfortunately, most things in the real world are non-linear, which sucks. One of the most common ways of dealing with this when using Kalman filters is to employ the extended Kalman filter.
The main difference between the EKF and standard KF is that the EKF is able to handle non-linear dynamics by linearizing the non-linear system around the Kalman filter estimate, and then the Kalman filter estimate is based on the linearized system. It’s a bit of a mouthful, but essentially we are just linearizing our system around our estimate, and then feeding that back in to the filter. It’s bootstrapping.
Let’s get crackin’!
For the case of the discrete time extended Kalman filter, we have the usual suspects of system and measurement equations, but this time the state transition matrix F and the output matrix H can be nonlinear.
We then initialize the EKF as before:
Once we let the EKF start rolling in measurements there is a lot more work to be done now that we are linearizing the system. For each time step we then perform the following step to linearize the state transition matrix about the previous steps a posteriori state estimate:
After computing the partial derivatives update the state estimate and estimation-error covariances:
The time update of the state estimate above just indicates to plug the previous steps a posteriori estimate back in to the original nonlinear system model.
With the a preori state estimate for the current time step calculated, we then linearize the output model and evaluate it about the a preori state estimate.
We then use the linearized output model evaluated about the a preori state estimate to calculate the Kalman gain, and therefore the a posteriori state estimate and a posteriori estimation-error covariance.
EKFs, The Popular Crowd Kalman Filter
The EKF is one of the most popular tools for state estimation that you’ll come across within the robotics community. As opposed to tools like the particle filter, the EKF is much more computationally efficient because it represents the belief by a multivariate Gaussian distribution. Just like the standard Kalman filter, each update of the EKF requires time , where k is the dimension of the measurement vector, and n is the dimension of the state vector.[2]
You may be thinking, “Surely, Eric, this is as deep as it goes,” but you’d be wrong. Why? Well, one of the limitations of the EKF is that we are approximating our state transition and measurement matrices by Taylor expansions (that whole partial derivative thing above). In most real-world applications these matrices are nonlinear (duh, that’s why we were using the EKF in the first place!) but if they are highly nonlinear about our evaluation point this approximation may not be good enough.
How Much More Complicated Can This Get?
Well, we have to keep grad students and profs busy, so there are lots of more complicated variations. We can represent posteriors using mixtures or sums of Gaussians, such is the case of the multi-hypothesis extended Kalman filter, or MHEKF. Then there’s the information filter, which propagates the inverse of the estimation-error covariance, which can be computationally more efficient if we have significantly more measurements than states. Then there’s the filter, which is actually less complicated because it’s been studied since the days of Newton (it involves a two state Newtonian dynamical system with a position measurement). We have fading memory Kalman filters for when we have a crap system model and we don’t want our estimate to diverge from the true state, The filter for when we need a very robust filter to minimize the worst-case estimation error, the hybrid extended Kalman filter, for when we want to combine continuous and discrete time dynamics, the second order extended Kalman filter where we employ a second order Taylor series expansion of our state transition and measurement matrices to reduce the linearization error of the standard EKF, the iterated extended Kalman filter where we perform our linearization process again (or as many times as we like) after getting our a posteriori state estimate. If we want to get even trickier there’s the unscented Kalman filter that aims to further reduce linearization errors present in the EKF by transforming our probability density functions through a nonlinear function (which is difficult) by means of deterministic vectors known as sigma points whose ensemble mean and covariance are equal to our state mean and estimation-error covariance. Finally, we have the very common particle filter that just brute forces its way through estimation, which is pretty awesome now that computation power is relatively cheap.
References
Simon, D. (2006). Optimal State Estimation. Hoboken, New Jersey: Wiley. ISBN: 9780471708582
Thrun, S., Burgard, W.,, Fox, D. (2005). Probabilistic robotics. Cambridge, Mass.: MIT Press. ISBN: 0262201623 9780262201629
They’re not really magic, and I’ll probably hate you if you say they are.
The Kalman filter, and variations thereof, are probably the most commonly come across optimal state estimators that you will find. They just work well and mathematically are pretty, well, badass. I’ve seen plenty of people use them despite knowing their noise characteristics, or really having too good of an idea of what the system processes are, and still work decently well when tuned. That said, one of the most common causes for failure of Kalman filtering is due to modeling errors.
Guts of the Kalman Filter
We’ve already talked about a few different flavors of least squares estimators, and the Kalman filter continues to build on these concepts. In the case of the recursive least squares estimator, we now only need to change the symbols we use slightly to denote a priori and a posteriori state estimates and covariances. Oh, and actually have an idea of what the hell it is our system is doing, along with its internal noise process. This then allows us to estimate what the next set of states will be for the system given our model of it, and also incorporates our actual measurements in to it. One of the beautiful things about the Kalman filter is that the Kalman gain term then selectively weighs how much we should trust our model versus our measurement given the measurement statistics.
With the extra complication of having to know how our system evolves in time a la its state transition matrix, we can describe the discrete-time Kalman filter by first modelling our dynamic system as follows:
Woah, woah, woah. There’s a whole other noise process now that we have to figure out what the hell to do with? That’s right! But fortunately for us the process noise covariance, Q, is often just used as a tuning parameter in the filter. As the process noise covariance is increased, the covariance between samples will increase, thereby making the Kalman filter gain coverge to a larger value, which will then cause a larger emphasis to be placed on measurements. From this it’s easy to see we can use Q to favor or devalue the effect of our measurements if we have the desire to do so.
Moving on to initializing the Kalman filter:
Where the refers to the initial a posteriori state estimate, and refers to the initial a posteriori covariance.
With this model and initialization, it’s time to just let the Kalman filter chug along with the following equations at each time step k = 1, 2, etc.
Where is the a priori state estimate, and is the a posteriori state estimate. The first representation of the a posteriori covariance is known as the Joseph stabilized version, and is the most robust, whereas the third version is much more succinct, but is less robust. If the second expression for the Kalman gain is used, so too must the second expression for the a posteriori covariance.
Cool Things to Take Away
In the measurement update equation above, the quantity is known as the innovations, which is simply the difference between the the actual measurement and the predicted measurement. This is the part of the measurement that contains new information about the state. As you can see, the Kalman filter then weights the innovations by the kalman gain, and then adds it to the a priori state estimate, to finally obtain the a posteriori state estimate. Therefore, the only difference between the a priori and a posteriori state estimate is that the latter takes the new measurement into account, whereas the former is the state estimate according to what our dynamic model predicts. If you’re coming at this from a mobile robotics application, people will generally refer the dynamic model as the motion model, and the state estimate the belief.
I won’t go into the proof, but the Kalman filter is the optimal filter given Gaussian noise processes. Even if the noise processes are not Gaussian, the Kalman filter is still the optimal linear filter.
I really like the little block diagram that wikipedia uses on their page for the Kalman filter; I think it does a pretty nice job of illustrating the flow of the filter.
In the above image, I would prefer it if the mean for the leftmost, blue, Gaussian was labelled and the mean for the center Gaussian was labelled , but I think you get the idea they are trying to convey.
Lastly, I feel like there isn’t much need in writing your own filter from scratch as there are a decent number of libraries out there that you can piggy back off of. If you want to give FilterPy a try, it has a class named kalman that will do basically what you’d like, otherwise there are libraries like PyKalman.
Verifying Your Kalman Filter Isn’t Broken and Final Thoughts
One of the easiest things to do to verify the performance of your Kalman filter is to monitor what the innovations are doing. The innovations should be a white noise process with zero mean with a covariance of
If we see that the innovations appear to be colored, nonzero-mean, or has the wrong covariance, then there is something wrong with the filter; this is usually due to an error in modelling.
Oh, also make sure your error covariance matrix, P is converging (kind of important).
Sometimes to tie a bunch of the concepts together people will refer to Kalman filters as Linear Quadratic Estimators, simply because we assume a linear system, and our cost minimization function is quadratic.
So, we’ve talked about least squares estimation and how we can weight that estimation based on our certainty in our measurements. Now let’s talk about when we want to do this shit online and roll in each subsequent measurement!
Things begin to get a bit more complicated now that we have an “update” step that requires us to fold in new information, but we are getting closer and closer to the more complicated Kalman filter. In order to fold in this newly acquired data, we add in a matrix, . known as the estimator gain matrix, or if you’re dealing with a Kalman filter it’s called the Kalman gain matrix, either way, it’s the same thing: just a weighting of how confident we are in our measurements based on their statistics.
We will therefore amend our state equations as follows:
The difference this time being that we compute based on the previous estimate, and the measurement .
For the sake of expediency I’m going to skip most of the derivation of this one because the matrix equations continue to get longer, so let’s just jump right to the useful part of it all.
Recursive Least Squares Estimation Algorithm
We begin by first initiating the estimator as follows:
Where is the estimation-error covariance. There’s a bit of a trick we play next to get the ball rolling: if we don’t know anything about x before measurements start rolling in, we set . If we know exactly what x is before measurements roll in we set . So, basically the less we know about x the larger we set our estimation-error covariance.
With the estimator initialized, let’s start chugging along. We update our estimate of x and the estimation-error covariance, P, with the following equations:
Where is the covariance of our zero-mean noise process, . In the real world this is literally just the variance in your measurement variable when your state is held constant. So, if our output measurement variable were, for example, the angular velocity of a table saw blade, we could run the table saw at constant velocity, collect our data, and determine R to be the variance in our angular velocity measurements.
Here’s a picture I found from researchgate[1] that illustrates the effect of a recursive least squares estimator (black line) on measured data (blue line). This scenario shows a RLS estimator being used to smooth data from a cutting tool. Don’t worry about the red line, that’s a bayesian RLS estimator.
Slightly Sexier Examples (Curve Fitting)
Despite what many people with their resistor based examples of what least squares estimators will tell you, we can actually do some pretty cool things with these guys. Take for example curve fitting. Let’s suppose we are measuring the altitude of a free falling object. From basic physics we know that the underlying governing equation for this is a quadratic function of time:
Where r is position, is the initial position, is the initial velocity, and a is the acceleration. If we then measure r at many different times and fit a quadratic to the resulting position vs time curve, we will have an estimate of our initial velocity and acceleration.
In this scenario, our output equation takes the form
From here, it’s just a simple matter of initializing the estimator and then letting the algorithm governed by the equations set out in 3 do its thing, or what ever other flavor of least squares estimation you prefer.
In the words of Jerry Smith, later days, amigo.
Resources
Mehta, Parikshit & Mears, Laine. (2014). Adaptive control for multistage machining process scenario—bar turning with varying material properties. International Journal of Advanced Manufacturing Technology. 10.1007/s00170-014-6739-x.
I figured I’d kind of skip over this variant in the least squares estimator, after all, my goal is to talk about all the stepping stones to get to the Kalman filter, and I’m a little impatient, but I like talking about the weighted least squares estimator because it shows that even if some of our measurements are less reliable than others we should never discard them. If we continue to run with the beat to death example of a resistor, let’s now assume we are using a couple different multimeters to make measurements, one that is really expensive and calibrated, and one that’s been purchased from Amazon for 10 dollars.
The above scenario essentially boils down to us saying we have more faith in one measuring device than the other, but how do we represent this in a mathematically meaningful way? With statistics!
Let’s take the same equations from our last little talk about least squares estimation, but modify them now by actually characterizing the noise that we are experiencing. Now, if we assume that the noise for each measurement is zero-mean and independent we can write our expectation and measurement covariance matrix as follows:
We then construct our cost function like we did before, but this time weigh the sum of squares equation by the variance in our measurements. This allows us to place more emphasis on measurements that are less noisy and less emphasis on measurements that are very noisy. This technique of weighing things by how much faith we have in measurements will continue to show up as we discuss “better” estimators. This weighting results in a cost function as follows:
Honestly, when we carry out the matrix multiplication shown above we get a pretty dumb and long looking equation that I don’t really care to type out, and unless you’re just looking for a proof for a homework assignment it doesn’t matter much. Let’s call it good enough to show that when we again take the partial derivative of our cost function with respect to we arrive at
It goes without saying that since we are inverting R in equation 3 it must be nonsingular, in other words, we have to assume that each of our measurements are affected by at least some amount of noise.
More Examples!
If we return to our example of estimating the resistance of a resistor, we can basically just employ equation 3 directly, which ends up being
This time, instead of just the average of measurements our solution becomes the weighted sum of measurements, where each measurement is weighted by the inverse of our uncertainty in that measurement.
Least squares estimators are typically used to determine a constant on the basis of several noisy measurements of that constant. Mathematically I think they’re pretty beautiful, and the derivation of them leads us to the somewhat ubiquitous Moore-Penrose pseudo inverse.
Let’s just jump right in!
Suppose we want to determine a “best” estimate of some state constant n-element state vector, x, and y is a k-element noisy measurement vector. Typically estimates of something are denoted as that “something” with a hat over it, so we will call our estimated vector . Let’s assume that the process governing this system is linear, otherwise our lives have just gotten a whole lot harder, such that each element of the measurement vector y is a linear combination of elements of the state vector, x, with some added noise on top.
Which can be written in matrix form simply as:
Now, let’s introduce something called the measurement residual, which is simply the difference between the noisy measurement (actual system output) and the estimated output.
So, as we can see from equation 3, the smaller the measurement residual becomes, in some sense, the better our estimate of that parameter is. Simply by inspection it makes sense that if our measurement residual becomes zero we have done a pretty good job estimating x.
Since we are dealing with least squares estimation, the above “some sense” is in a least squares sense, so we will construct a cost function, J, that is the sum of squares of our measurement residuals as follows:
Now, let’s substitute equation 3 into equation 4 so we obtain the cost function in terms of our measurement vector, y, the output matrix, H, and estimated state vector .
Cool, now that we have our cost function constructed, the next step is to minimize said function with respect to . Remembering back to calc 3 we know that in order to minimize a multivariable equation with respect to one of its variables we must compute the partial derivative and set it equal to zero.
If we gently massage equation 6 so as to solve for our state estimate we obtain:
Where is the left pseudo inverse. The pseudo inverse exists if and H is full rank. This just means that we need to have more measurements than there are number of variables and the measurements must be linearly independent.
Example Time!
The example that I always see given for this simple problem is that of estimating the resistance of an unmarked resistor based on k measurements from a multimeter. In this scenario our state variable x is the resistance of the resistor, and y are our noisy measurements from the multimeter.
which again just reduces to the simple matrix equation
What the hell, our output matrix isn’t there! Well, it is, it’s just a k x 1 matrix filled with 1’s. Now, if we just plug this into equation 7 from above, our optimal (in the sense of least squares) estimate of the state x is simply
In this, almost stupidly, simple example, the least squares estimate reduces to just what a normal person would have done and is the average of the noisy measurements.
This is going to be a super quick and dirty writeup until I take the time to make it more presentable, but here we go!
For the time being this is mostly going to just be a link and short description of my allan variance github repo used to create synthetic IMU error models using a first order Gauss-Markov process: https://github.com/EVictorson/allan_variance
Also, I’m going to REALLY simplify the technical discussion here because this seems to be one of those areas where PhDs in control theory like to start waving their… boy parts… around to show who knows more about what, which is unnecessary.
Allan Variance Background
The Allan Variance (AVAR) is historically used as a measure of frequency stability in clocks, oscillators, and amplifiers. It is named after the one and only David W. Allan.
Mathematically the AVAR is is expressed as:
While the Allan Deviation is, as you may expect from basic statistics:
We often see the M-sample Allan variance, which is a measure of frequency stability using M samples, time T between measurements, and observation time tau. The M-sample Allan variance is expressed as:
To explain the AVAR as academically as you can in as few words as possible is to say that it is defined as one half of the time average of the squares of the differences between successive readings of the frequency deviation sampled over the sampling period. The Allan variance depends on the time period used between samples: therefore it is a function of the sample period, commonly denoted as tau, likewise the distribution being measured, and is displayed as a graph rather than a single number. (Editors note: TL;DR) A low Allan variance is characteristic of a clock with good stability over the measured period. [1]
The results of AVAR or ADEV are related to five basic noise terms appropriate for inertial sensor data, namely:
Quantization noise
Angle Random Walk
Bias Instability
Rate Random Walk
Rate Ramp
Now, you may ask, why the hell are we using something that was designed to measure the frequency stability of clocks in characterizing errors of an IMU? The answer is, to put it simply, we typically separate the errors of inertial measurement devices into two groups: deterministic errors like bias and nonlinearity, and stochastic processes like the ones mentioned above. Within the field of system dynamics, everything can be decomposed into frequency domain, and we are therefore concerned about the contribution to errors from different frequency sources. As wikipedia succinctly puts it: “The Allan variance is intended to estimate stability due to noise processes and not that of systematic errors or imperfections such as frequency drift or temperature effects. The Allan variance and Allan deviation describe frequency stability.” Basically, the easiest way to think about this, if you’ve taken an undergraduate controls course, this will be a piece-meal Bode plot with different error frequencies. I’ll expand on this in a minute, but that’s basically what we are dealing with.
Again, the Allan variance / Allan deviation is nothing more than a Bode plot that analyzes the magnitude of different noise sources with differing frequency power. This will cause different contributing noise terms to appear with differing slopes on the Allan deviation plot; these differing slopes making it easy to see that each noise process differs by an integrator (1/s).
The following error terms are the ones most commonly used, and can be distinguished on the Allan Variance / Deviation plot with their corresponding slopes.
Quantization Noise: slope -1
Quantization noise is Gaussian and zero mean. It is strictly due to the digital nature of ring laser gyro outputs.
Angle Random Walk: slope = -1/2
ARW is high frequency noise that can be obvserved as a short-term variation in the sensor output. After integration, it causes random error in angle with distribution that is proportional to the square root of the elapsed time. It is often thought to be from randomized dither and the spontaneous emission of photons for a ring laser gyro.
Bias Instability: slope = 0
BI has an impact on long-term stability. It is a slowly fluctuating error so it appears in low frequencies as 1/f (pink, or flicker) noise. For a gyroscope, this measures how the bias of the sensor changes over a specified period of time at a constant temperature. For a ring laser gyro this noise originates in the discharge assembly, electronics, and other components susceptible to random flickering.
Rate Random Walk: slope = 1/2
RRW basically characterizes the time scale over which changes in the bias offset occur and can give an idea of when recalibration of sensors should occur. This random process is of uncertain origin, possibly a limiting case of an exponentially correlated noise with a very long correlation time. Mechanical as well as rate biased laser gyros exhibit this noise term.
Rate Ramp: slope = 1
Slow monotonic change of output over a long time period. This is more of a deterministic error rather than random noise. Its presence in the data may indicate a very slow monotonic change of the ring laser gyro intensity persisting over a very long period of time.
So, what do one of these bad boys look like you may ask? Well, to steal, er borrow, an image from Freescale’s application note AN5087 “Allan Variance: Noise analysis for gyroscopes” [2] we see something like this:
Allan Deviation Plot, courtesy Freescale AN5087
In the above plot, and with all AVAR / ADEV plots, the horizontal axis is the averaging time, an the vertical axis is either the AVAR or ADEV, ADEV in the case of the plot above.
Empirical Data Acquisition and Testing
For an in-depth tutorial on how best to collect data to perform AVAR, see Section B.4 of [4]. To summarize their recommendations, you can select the sample rate to be at least twice the sample bandwidth. The record length should be at least several times the required performance interval. The recommended approach is to limit the time/frequency domain dynamic range to about 3 orders of magnitude. In practice this is done by dividing the total range into overlapping intervals of geometrically increasing lengths. Thus, the high frequency data is acquired for a short period of time. Lower frequency data is filtered (integrated) and acquired for a longer period; e.g. 100 us data is collected for 0.1s, 0.01s data for 10s, 1s data for 1000s, and 100s data for 10^5 s. The appropriate sampling rates/ record lengths should be chosen to overap about one decade of frequency (time).
If we are considering a gyroscope, the Allan variance can be defined in terms of the output rate, , or the output angle as
The lower integration limit is not present in equation 4 because only angle differences are employed in all of the definitions.
The angle measurements that are fed into equation 4 are made at times , where k varies from 1 to N (the number of samples), and the sample period is . For a discrete set of samples, a cumulative sum can be used to give N values of . In this case the cumulative sum of the gyro output samples at each is taken and each sum obtained is then multiplied by the sample period to give N values of . [2]
A general heuristic to use is to set the averaging time to be , where m is the averaging factor. The averaging factor can be chosen arbitrarily as some value according the inequality . [2]
Cool, now that we’ve got our values of calculated, we compute the Allan variance with the following equation:
Equation 5 represents Allan variance as a function of and < > is the ensemble average. Upon expanding the ensemble average in equation 5 we obtain the following estimate of the Allan variance:
For those who care, and if you want to swing your boy parts around in public, the Allan variance is related to the two-sided power spectral density, by:
Cool, so hopefully if you do this correctly you’ll have a plot that looks something like this:
Simulation and Validation
Alrighty, so we can get a plot from our time series data easily enough, what next? Well, if we presume to already know the noise coefficients we can simulate the Allan variance plot and compare the two, or we can try to characterize the noise coefficients from the Allan variance plot itself.
For simulation and modelling purposes, typically a first order Gauss-Markov process is used to model these kinds of errors, which is just an exponentially correlated, noise driven stochastic process characterized by the following differential equation:
Which is ultimately just an exponentially decaying autoregressive term with driven white noise. The discrete time version of this is:
The first order gauss-markov process may also be defined in terms of its autocorrelation function:
where is the entire process variation (NOT JUST THE DRIVEN NOISE VARIATION), is the inverse of the correlation time, , and is the autocorrelation time lag.
For sufficiently long time series (much longer than the time constant), the autocorrelation plot of the first order Gauss-Markov process can verify the correlation time, which is the time lag at which , and the entire time series variance will appear as the peak at time lag = 0. Note that the driven noise standard deviation cannot be validated via autocorrelation. Also note that matlab has two different autocorrelation functions that will produce slightly different results if your time scales are short (autocorr and xcorr), as well as an autocovariance function, xcov. Autocorr and xcov are normalized by the process mean such that a constant process will have a steady autocorrelation (autocorrelation is just autocovariance scaled by the inverse of the process variance). xcorr, however, does not do this, so a constant process will have a decaying autocorrelation as the time lag increases, which results in a shortening of the summation by 1 element each iteration.
For process lengths on the order of magnitude of the time constant or less the process will be dominated by the integrated white noise term, resulting in a random walk. For time scales much longer than the time constant the exponentially correlated term will begin to be apparent. This can be see on an Allan deviation plot, where for sampling intervals much shorter than the time constant the Gauss-Markov Allan variance reduces to that of a singly integrated white noise process (rate random walk), whose slope is +1/2, and the noise magnitude (standard deviation) may be picked off by finding the intersection of the +1/2 slope line and sampling_interval = 3. This can also be verified by differentiating this time series to obtain Gaussian noise, whose Allan deviation has a slope of -1/2, and the noise magnitude is interpreted as the intersection of this line with sampling_interval = 1.
For process time scales large enough to see the decay time constant, and Allan deviations with sampling intervals ranging from much less than the time constant to sampling intervals much larger than the time constant, the slope will transition from +1/2 for sampling intervals much shorter than the time constant, to 0 as the sampling interval approaches the time constant at it’s maxima, to -1/2 as the interval becomes much larger than the time constant.
When multiple gauss markov processes are added together it will be nearly impossible to pick apart any of these parameters, but when run individually the driven noise magnitude (qc) and time constant (Tc) can be found on the allan deviation plot as follows: Tc = argmax_sampling_interval / 1.89, where argmax_sampling_interval is the allan deviation sampling interval that maximizes the allan deviation. The driven noise magnitude may then be found with the following relationship:
where is the Allan deviation maxima.
If the combined output of all of these Gauss-Markov processes are analyzed, the only easy thing to pick off will be the velocity random walk / angle random walk, which may be found by fitting a line to the segment with a slope of -1/2 and finding the intersection of this line with tau = 1.
Characterizing Error Sources
Angle Random Walk
Angle random walk appears on the AVAR plot as the following equation:
where N is the angle random walk coefficient. In a log-log plot of vs ARW has a slope of -1/2. The numerical value of N can be obtained by reading the -1/2 slope line at .
Bias Instability
Bias instability appears on the AVAR plot as the following cumbersome equation:
Where x is , B is the bias instability coefficient is the cutoff frequency, and Ci is the cosine-integral function.
As you can see it’s probably a bit easier to just pick off the part of the AVAR plot that has a slope of 0.
Rate Random Walk
Rate random walk appears on the AVAR plot with the following equation:
Where K is the rate random walk coefficient.
Because we are essentially dealing with Bode plots, the presence of in the numerator indicates we will be searching for a slope of +1/2. The magnitude of this noise can be read off the +1/2 slope line at .
Rate Ramp
Rate ramp appears on the AVAR plot with the following equation:
Where R is the rate ramp coefficient.
With one more power of tau in the numerator we are therefore looking for a slope of +1. The magnitude of R can be obtained from the +1 slope line at .
Quantization Noise
Quantization noise appears on the AVAR plot with the following equation:
Where Q is the quantization noise coefficient.
Quantization noise appears with a slope of -1 on the log-log plot and can be read off the intersection of the line with slope -1 and .
Exponentially Correlated (Markov) Noise
Markov noise appears on the AVAR plot as:
Where qc is the noise amplitude, and Tc is the correlation time as noted above.
It is easier to view the behavior of the Markov noise at various limits of the equation. For cases with we obtain:
Which is the Allan variance for angle random walk where N = qcTc is the angle random walk coefficient. For we obtain:
Which is the Allan variance for rate random walk.
Sinusoidal Noise
Also, sinusoidal noise exists, but I won’t talk about it because it hasn’t concerned any of my work. Just know it exists.
Now, if we take and superimpose all of these noise sources on one plot we should see a piece-wise representation of the empirically derived plot like that shown in [8]:
IEEE Standard Specification Format Guide and Test Procedure for Single-Axis Interferometric Fiber Optic Gyros. IEEE std 952-1997 (R2008)
IEEE Standard Specification Format Guide and Test Procedure for Single-Axis Laser Gyros. IEEE std 647-1995
Kirkko-Jaakkola, M., Collin, J., & Takala, J. (2012). Bias Prediction for MEMS Gyroscopes. IEEE Sensors Journal, 12(6), 2157-2163. DOI: 10.1109/JSEN.2012.2185692
Peng-Yu, C. (2015). Experimental Assessment of MEMS INS Stochastic Error Model. Graduate Thesis, The Ohio Sate University, Department of Civil Engineering.
Martin, V. MEMS Gyroscope Performance Comparison Using Allan Variance Method, Brno University of Technology.























 is simply a tuning parameter used to weigh which part of our minimization problem we want to place more importance on. Is it more important for us to minimize the energy of the controlled output, z? Then select
is simply a tuning parameter used to weigh which part of our minimization problem we want to place more importance on. Is it more important for us to minimize the energy of the controlled output, z? Then select 
 and
and  are symmetric positive-definite matrices.
are symmetric positive-definite matrices.





 and
and  matrices? And second, how the hell do we actually solve that algebraic Riccati equation?
matrices? And second, how the hell do we actually solve that algebraic Riccati equation? . From here we just vary the single parameter
. From here we just vary the single parameter  until we get something that has a decent response.
until we get something that has a decent response.



![\begin{aligned} 2) \displaystyle \qquad \hat{x}_0^+ &= E(x_0)\\ P_0^+ &= E \left[ \left(x_0 - \hat{x}_0^+ \right ) \left(x_0 - \hat{x}_0^+ \right)^T \right ] \\ \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D++2%29+%5Cdisplaystyle+%5Cqquad+%5Chat%7Bx%7D_0%5E%2B+%26%3D+E%28x_0%29%5C%5C++P_0%5E%2B+%26%3D+E+%5Cleft%5B+%5Cleft%28x_0+-+%5Chat%7Bx%7D_0%5E%2B+%5Cright+%29+%5Cleft%28x_0+-+%5Chat%7Bx%7D_0%5E%2B+%5Cright%29%5ET+%5Cright+%5D+%5C%5C++%5Cend%7Baligned%7D++&bg=ffffff&fg=000&s=1&c=20201002)



![\begin{aligned} 6) \displaystyle \qquad K_k &= P_k^- H_k^T \left( H_k P_k^- H_k^T + M_k R_k M_k^T \right ) ^{-1}\\ \hat{x}_k^+ &= \hat{x}_k^- + K-k \left [y_k - h_k(\hat{x}_k^-, 0) \right ]\\ P_k^+ &= \left (I - K_k H_k \right ) P_k^- \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D++6%29+%5Cdisplaystyle+%5Cqquad+K_k+%26%3D+P_k%5E-+H_k%5ET+%5Cleft%28+H_k+P_k%5E-+H_k%5ET+%2B+M_k+R_k+M_k%5ET+%5Cright+%29+%5E%7B-1%7D%5C%5C++%5Chat%7Bx%7D_k%5E%2B+%26%3D+%5Chat%7Bx%7D_k%5E-+%2B+K-k+%5Cleft+%5By_k+-+h_k%28%5Chat%7Bx%7D_k%5E-%2C+0%29+%5Cright+%5D%5C%5C++P_k%5E%2B+%26%3D+%5Cleft+%28I+-+K_k+H_k+%5Cright+%29+P_k%5E-++%5Cend%7Baligned%7D++&bg=ffffff&fg=000&s=1&c=20201002)
 , where k is the dimension of the measurement vector, and n is the dimension of the state vector.[2]
, where k is the dimension of the measurement vector, and n is the dimension of the state vector.[2] filter, which is actually less complicated because it’s been studied since the days of Newton (it involves a two state Newtonian dynamical system with a position measurement). We have fading memory Kalman filters for when we have a crap system model and we don’t want our estimate to diverge from the true state, The
filter, which is actually less complicated because it’s been studied since the days of Newton (it involves a two state Newtonian dynamical system with a position measurement). We have fading memory Kalman filters for when we have a crap system model and we don’t want our estimate to diverge from the true state, The  filter for when we need a very robust filter to minimize the worst-case estimation error, the hybrid extended Kalman filter, for when we want to combine continuous and discrete time dynamics, the second order extended Kalman filter where we employ a second order Taylor series expansion of our state transition and measurement matrices to reduce the linearization error of the standard EKF, the iterated extended Kalman filter where we perform our linearization process again (or as many times as we like) after getting our a posteriori state estimate. If we want to get even trickier there’s the unscented Kalman filter that aims to further reduce linearization errors present in the EKF by transforming our probability density functions through a nonlinear function (which is difficult) by means of deterministic vectors known as sigma points whose ensemble mean and covariance are equal to our state mean and estimation-error covariance. Finally, we have the very common particle filter that just brute forces its way through estimation, which is pretty awesome now that computation power is relatively cheap.
filter for when we need a very robust filter to minimize the worst-case estimation error, the hybrid extended Kalman filter, for when we want to combine continuous and discrete time dynamics, the second order extended Kalman filter where we employ a second order Taylor series expansion of our state transition and measurement matrices to reduce the linearization error of the standard EKF, the iterated extended Kalman filter where we perform our linearization process again (or as many times as we like) after getting our a posteriori state estimate. If we want to get even trickier there’s the unscented Kalman filter that aims to further reduce linearization errors present in the EKF by transforming our probability density functions through a nonlinear function (which is difficult) by means of deterministic vectors known as sigma points whose ensemble mean and covariance are equal to our state mean and estimation-error covariance. Finally, we have the very common particle filter that just brute forces its way through estimation, which is pretty awesome now that computation power is relatively cheap.

![\begin{aligned} 2) \displaystyle \qquad \hat{x}_0^+ &= E(X_0)\\ P_0^+ &= E \left [ (x_0 - \hat{x}_0^+)(x_0 - x_0^+) \right ] \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D++2%29+%5Cdisplaystyle+%5Cqquad+%5Chat%7Bx%7D_0%5E%2B+%26%3D+E%28X_0%29%5C%5C++P_0%5E%2B+%26%3D+E+%5Cleft+%5B+%28x_0+-+%5Chat%7Bx%7D_0%5E%2B%29%28x_0+-+x_0%5E%2B%29+%5Cright+%5D++%5Cend%7Baligned%7D++&bg=ffffff&fg=000&s=1&c=20201002)
 refers to the initial a posteriori state estimate, and
refers to the initial a posteriori state estimate, and  refers to the initial a posteriori covariance.
refers to the initial a posteriori covariance.![\begin{aligned} 3) \displaystyle \qquad P_k^- &= F_{k-1}P_{k-1}^+ F_{k-1}^T + Q_{k-1}\\ K_K &= P_k^- H_k^T \left (H_k P_k^- H_k^T + R_k \right ) ^{-1} \\ &= P_k^+ H_K^T R_k^{-1} \\ \hat{x}_k^- &= F_{k-1} \hat{x}_{k-1}^+ + G_{k-1} u_{k-1} \\ \hat{x}_k^+ &= \hat{x}_k^- + K_k \left( y_k - H_k \hat{x}_k^- \right ) \\ P_k^+ &= \left (I - K_kH_k \right ) P_k^- \left (I- K_k H_k \right )^T + K_k R_k K_k^T \\ &= \left [ (P_k^-)^{-1} + H_k^T R_k^{-1} H_k \right ] ^{-1}\\ &= \left (I - K_k H_k \right )P_K^- \\ \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D++3%29+%5Cdisplaystyle+%5Cqquad+P_k%5E-+%26%3D+F_%7Bk-1%7DP_%7Bk-1%7D%5E%2B+F_%7Bk-1%7D%5ET+%2B+Q_%7Bk-1%7D%5C%5C++K_K+%26%3D+P_k%5E-+H_k%5ET+%5Cleft+%28H_k+P_k%5E-+H_k%5ET+%2B+R_k+%5Cright+%29+%5E%7B-1%7D+%5C%5C++%26%3D+P_k%5E%2B+H_K%5ET+R_k%5E%7B-1%7D+%5C%5C++%5Chat%7Bx%7D_k%5E-+%26%3D+F_%7Bk-1%7D+%5Chat%7Bx%7D_%7Bk-1%7D%5E%2B+%2B+G_%7Bk-1%7D+u_%7Bk-1%7D+%5C%5C++%5Chat%7Bx%7D_k%5E%2B+%26%3D+%5Chat%7Bx%7D_k%5E-+%2B+K_k+%5Cleft%28+y_k+-+H_k+%5Chat%7Bx%7D_k%5E-+%5Cright+%29+%5C%5C++P_k%5E%2B+%26%3D+%5Cleft+%28I+-+K_kH_k+%5Cright+%29+P_k%5E-+%5Cleft+%28I-+K_k+H_k+%5Cright+%29%5ET+%2B+K_k+R_k+K_k%5ET+%5C%5C++%26%3D+%5Cleft+%5B+%28P_k%5E-%29%5E%7B-1%7D+%2B+H_k%5ET+R_k%5E%7B-1%7D+H_k+%5Cright+%5D+%5E%7B-1%7D%5C%5C++%26%3D+%5Cleft+%28I+-+K_k+H_k+%5Cright+%29P_K%5E-+%5C%5C++%5Cend%7Baligned%7D++&bg=ffffff&fg=000&s=1&c=20201002)
 is the a priori state estimate, and
is the a priori state estimate, and  is the a posteriori state estimate. The first representation of the a posteriori covariance is known as the Joseph stabilized version, and is the most robust, whereas the third version is much more succinct, but is less robust. If the second expression for the Kalman gain is used, so too must the second expression for the a posteriori covariance.
is the a posteriori state estimate. The first representation of the a posteriori covariance is known as the Joseph stabilized version, and is the most robust, whereas the third version is much more succinct, but is less robust. If the second expression for the Kalman gain is used, so too must the second expression for the a posteriori covariance. is known as the innovations, which is simply the difference between the the actual measurement and the predicted measurement. This is the part of the measurement that contains new information about the state. As you can see, the Kalman filter then weights the innovations by the kalman gain, and then adds it to the a priori state estimate, to finally obtain the a posteriori state estimate. Therefore, the only difference between the a priori and a posteriori state estimate is that the latter takes the new measurement into account, whereas the former is the state estimate according to what our dynamic model predicts. If you’re coming at this from a mobile robotics application, people will generally refer the dynamic model as the motion model, and the state estimate the belief.
is known as the innovations, which is simply the difference between the the actual measurement and the predicted measurement. This is the part of the measurement that contains new information about the state. As you can see, the Kalman filter then weights the innovations by the kalman gain, and then adds it to the a priori state estimate, to finally obtain the a posteriori state estimate. Therefore, the only difference between the a priori and a posteriori state estimate is that the latter takes the new measurement into account, whereas the former is the state estimate according to what our dynamic model predicts. If you’re coming at this from a mobile robotics application, people will generally refer the dynamic model as the motion model, and the state estimate the belief.


 . known as the estimator gain matrix, or if you’re dealing with a Kalman filter it’s called the Kalman gain matrix, either way, it’s the same thing: just a weighting of how confident we are in our measurements based on their statistics.
. known as the estimator gain matrix, or if you’re dealing with a Kalman filter it’s called the Kalman gain matrix, either way, it’s the same thing: just a weighting of how confident we are in our measurements based on their statistics.
 based on the previous estimate,
based on the previous estimate,  and the measurement
and the measurement  .
.![\begin{aligned} 2) \displaystyle \qquad \hat{x}_0 &= E(x)\\ P_0 &= E \left [ (x - \hat{x}_0)(x - \hat{x}_0)^T \right ] \\ \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D++2%29+%5Cdisplaystyle+%5Cqquad+%5Chat%7Bx%7D_0+%26%3D+E%28x%29%5C%5C++P_0+%26%3D+E+%5Cleft+%5B+%28x+-+%5Chat%7Bx%7D_0%29%28x+-+%5Chat%7Bx%7D_0%29%5ET+%5Cright+%5D+%5C%5C++%5Cend%7Baligned%7D++&bg=ffffff&fg=000&s=1&c=20201002)
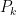 is the estimation-error covariance. There’s a bit of a trick we play next to get the ball rolling: if we don’t know anything about x before measurements start rolling in, we set
is the estimation-error covariance. There’s a bit of a trick we play next to get the ball rolling: if we don’t know anything about x before measurements start rolling in, we set  . If we know exactly what x is before measurements roll in we set
. If we know exactly what x is before measurements roll in we set  . So, basically the less we know about x the larger we set our estimation-error covariance.
. So, basically the less we know about x the larger we set our estimation-error covariance.
 is the covariance of our zero-mean noise process,
is the covariance of our zero-mean noise process, 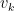 . In the real world this is literally just the variance in your measurement variable when your state is held constant. So, if our output measurement variable were, for example, the angular velocity of a table saw blade, we could run the table saw at constant velocity, collect our data, and determine R to be the variance in our angular velocity measurements.
. In the real world this is literally just the variance in your measurement variable when your state is held constant. So, if our output measurement variable were, for example, the angular velocity of a table saw blade, we could run the table saw at constant velocity, collect our data, and determine R to be the variance in our angular velocity measurements.

 is the initial position,
is the initial position,  is the initial velocity, and a is the acceleration. If we then measure r at many different times and fit a quadratic to the resulting position vs time curve, we will have an estimate of our initial velocity and acceleration.
is the initial velocity, and a is the acceleration. If we then measure r at many different times and fit a quadratic to the resulting position vs time curve, we will have an estimate of our initial velocity and acceleration.![\begin{aligned} 5) \displaystyle \qquad y_k &= x_1 + x_2 t_k + x_3 t_k^2 + v_k \\ E(v_k^2) &= R_k \\ H_k &= \left [ 1 \, t_k \, t_k^2 \right ] \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D++5%29+%5Cdisplaystyle+%5Cqquad+y_k+%26%3D+x_1+%2B+x_2+t_k+%2B+x_3+t_k%5E2+%2B+v_k+%5C%5C++E%28v_k%5E2%29+%26%3D+R_k+%5C%5C++H_k+%26%3D+%5Cleft+%5B+1+%5C%2C+t_k+%5C%2C+t_k%5E2+%5Cright+%5D++%5Cend%7Baligned%7D++&bg=ffffff&fg=000&s=1&c=20201002)


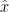 we arrive at
we arrive at








 is the left pseudo inverse. The pseudo inverse exists if
is the left pseudo inverse. The pseudo inverse exists if  and H is full rank. This just means that we need to have more measurements than there are number of variables and the measurements must be linearly independent.
and H is full rank. This just means that we need to have more measurements than there are number of variables and the measurements must be linearly independent.







 , or the output angle as
, or the output angle as
 , where k varies from 1 to N (the number of samples), and the sample period is
, where k varies from 1 to N (the number of samples), and the sample period is 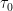 . For a discrete set of samples, a cumulative sum can be used to give N values of
. For a discrete set of samples, a cumulative sum can be used to give N values of  . In this case the cumulative sum of the gyro output samples at each
. In this case the cumulative sum of the gyro output samples at each  is taken and each sum obtained is then multiplied by the sample period
is taken and each sum obtained is then multiplied by the sample period  , where m is the averaging factor. The averaging factor can be chosen arbitrarily as some value according the inequality
, where m is the averaging factor. The averaging factor can be chosen arbitrarily as some value according the inequality  . [2]
. [2] 
 and < > is the ensemble average. Upon expanding the ensemble average in equation 5 we obtain the following estimate of the Allan variance:
and < > is the ensemble average. Upon expanding the ensemble average in equation 5 we obtain the following estimate of the Allan variance:
 by:
by:




 is the entire process variation (NOT JUST THE DRIVEN NOISE VARIATION),
is the entire process variation (NOT JUST THE DRIVEN NOISE VARIATION),  is the inverse of the correlation time,
is the inverse of the correlation time,  , and
, and  , and the entire time series variance will appear as the peak at time lag = 0. Note that the driven noise standard deviation cannot be validated via autocorrelation. Also note that matlab has two different autocorrelation functions that will produce slightly different results if your time scales are short (autocorr and xcorr), as well as an autocovariance function, xcov. Autocorr and xcov are normalized by the process mean such that a constant process will have a steady autocorrelation (autocorrelation is just autocovariance scaled by the inverse of the process variance). xcorr, however, does not do this, so a constant process will have a decaying autocorrelation as the time lag increases, which results in a shortening of the summation by 1 element each iteration.
, and the entire time series variance will appear as the peak at time lag = 0. Note that the driven noise standard deviation cannot be validated via autocorrelation. Also note that matlab has two different autocorrelation functions that will produce slightly different results if your time scales are short (autocorr and xcorr), as well as an autocovariance function, xcov. Autocorr and xcov are normalized by the process mean such that a constant process will have a steady autocorrelation (autocorrelation is just autocovariance scaled by the inverse of the process variance). xcorr, however, does not do this, so a constant process will have a decaying autocorrelation as the time lag increases, which results in a shortening of the summation by 1 element each iteration.
 is the Allan deviation maxima.
is the Allan deviation maxima.
 vs
vs  .
.![13) \displaystyle \qquad \sigma^2(\tau) = \frac{2B^2}{\pi}\left [ln 2 - \frac{sin^3(x)}{2x^2}\left (sin(x) + 4xcos(x)\right ) + Ci(2x) - Ci(4x) \right ]](https://s0.wp.com/latex.php?latex=13%29+%5Cdisplaystyle+%5Cqquad++%5Csigma%5E2%28%5Ctau%29+%3D+%5Cfrac%7B2B%5E2%7D%7B%5Cpi%7D%5Cleft+%5Bln+2+-+%5Cfrac%7Bsin%5E3%28x%29%7D%7B2x%5E2%7D%5Cleft+%28sin%28x%29+%2B+4xcos%28x%29%5Cright+%29+%2B+Ci%282x%29+-+Ci%284x%29+%5Cright+%5D&bg=ffffff&fg=000&s=1&c=20201002)
 ,
,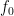 is the cutoff frequency, and
is the cutoff frequency, and
 .
.
 .
.
 .
.![17) \displaystyle \qquad \sigma^2(\tau) = \frac{(q_c T_c)^2}{\tau}\left [1- \frac{T_c}{2\tau}\left (3-4e^{-\frac{\tau}{T_c}}+e^{-\frac{2\tau}{T_c}}\right )\right ]](https://s0.wp.com/latex.php?latex=17%29+%5Cdisplaystyle+%5Cqquad+%5Csigma%5E2%28%5Ctau%29+%3D+%5Cfrac%7B%28q_c+T_c%29%5E2%7D%7B%5Ctau%7D%5Cleft+%5B1-+%5Cfrac%7BT_c%7D%7B2%5Ctau%7D%5Cleft+%283-4e%5E%7B-%5Cfrac%7B%5Ctau%7D%7BT_c%7D%7D%2Be%5E%7B-%5Cfrac%7B2%5Ctau%7D%7BT_c%7D%7D%5Cright+%29%5Cright+%5D&bg=ffffff&fg=000&s=1&c=20201002)
 we obtain:
we obtain:
 we obtain:
we obtain:
