
The second project in the computer vision oriented term 1 tasks the student to train a classifier to correctly classify signs using a convolutional neural network constructed in python using TensorFlow. My full github repo for the project is located here.
The primary CNN model used to solve this classification problem is a modified LeNet architecture with the addition of dropout layers between fully connected layers to prevent overfitting.
CNN Architecture
The standard LeNet-5 architecture is shown below, which is retrieved from the original paper.

The final architecture used is summarized below:
| Layer | Description |
| Input | 32x32x3 RGB image |
| Convolution 5×5 | 1×1 stride, valid padding, outputs 28x28x6 |
| RELU | |
| Max pooling | 2×2 stride, outputs 14x14x6 |
| Convolution 5×5 | 1×1 stride, valid padding, outputs 10x10x16 |
| RELU | |
| Max pooling | 2×2 stride, outputs 5x5x16 |
| Fully connected | 400 inputs, 120 outputs |
| RELU | |
| Dropout | Keep prob = 0.5 |
| Fully connected | 120 inputs, 84 outputs |
| RELU | |
| Dropout | Keep prob = 0.5 |
| Fully Connected | 84 inputs, 43 outputs |
| Softmax |
CNN Building Blocks
Neurons
As with standard neural networks, at the core of the convolutional neural network are still neurons, connected by synapses, which compute a dot product of inputs and weights, add to it a bias, pass this to an activation function, and then output this to the next layer.

Convolutional Layer
As you may expect, the convolutional layer is the core building block of convolutional neural networks. The convolutional layer consists of a set of learnable filters, or kernels, that are convolved with the input, in this case a 3 channel image.
During the forward pass, each kernel (there may be more than one), is convolved spatially across the input image, thereby creating a 2-dimensional activation map of that kernel. This results in the network learning a kernel (filter) that will activate when it detects a specific type of feature at a certain spatial position in the input image.

Local Connectivity
Due to the high dimensionality of images, if we were to connect every neuron in one volume to everyone neuron in the next, we would have an almost crazy number of parameters, which would result in a very high computational expense. CNNs therefore depend on the concept of local connectivity, and receptive field. The receptive field, to put it simply, is the size of the kernel used in convolution, which results in only local spatial connections between layers.
Activation Functions
Rectified linear units, or ReLUs, were used as activation functions for the traffic sign classifier CNN. When selecting an activation function, the designer should note that only nonlinear activation functions allow neural networks to compute nontrivial problems using only a small number of nodes. In fact, when a nonlinear activation function is used, then a two-layer neural network can be proven to be a universal function approximator.
Exponential Linear Unit (ELU)


Rectified Linear Unit (ReLU)


Hyperbolic Tangent Function


Logistic Sigmoid


Softmax
The softmax is used in the last fully connected layer to be able to convert outputs from the previous layer into probabilities for each output class. Mathematically, it may be defined as follows:

The ReLU is often preferred to other nonlinear activation functions because it trains the neural network several times faster without a significant penalty to the generalization accuracy.
Alternative nonlinear activation functions that are sometimes used include the hyperbolic tangent function, the exponential linear unit, and the logistic sigmoid function. The ELU is a function that tends to converge cost to zero fast and produce accurate results. The ELU is very similar to the ReLU, except that negative inputs result in a non-zero activation that smoothly becomes equal to 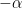
Pooling Layers
Pooling layers act to non-linearly downsample the input image. This is necessary because, at their core, neural networks act to reduce the dimensionality of their inputs; for classification afterall, we need to go from an input image of mxn pixels, with a depth of 3, into a certain class, which is a single output. In other words, pooling layers combine the outputs of neuron clusters in the previous layer into a single neuron input in the next layer.
Max pooling is one of the more common types of pooling functions used. In essence, they downsample by extracting the maximum value in a certain filter space. The image below, taken from wikipedia, illustrates how this is performed for a max pooling filter of dimensionality 2×2 and stride of 2.

Fully Connected Layers
Like the name suggests, fully connected layers connect every neuron in one layer to every neuron in the next layer. Fully connected layers typically appear at the end of a network and serve as the final, high-level reasoning device within CNNs.
The output from the convolutional, pooling, and other layers in a CNN represent high-level features of an input image. It is the job of the fully connected layer to use these features to classify the input image into the appropriate classes based on the training data.
Loss Layers
I mentioned the softmax function above, which is one example of a loss function used in loss layers.
In the traffic sign classifier problem I utilized a softmax cross entropy loss function as the loss operation to be minimized.
Utilizing Dropout to Prevent Overfitting
Dropout is simply a regularization technique that aims to prevent overfitting by randomly, or otherwise, dropping out units in a neural network.
Writeup and Results
The student is provided pickled data that contains a dictionary with 4 key/value pairs:
'features'is a 4D array containing raw pixel data of the traffic sign images, (num examples, width, height, channels).'labels'is a 1D array containing the label/class id of the traffic sign. The filesignnames.csvcontains id -> name mappings for each id.'sizes'is a list containing tuples, (width, height) representing the original width and height the image.'coords'is a list containing tuples, (x1, y1, x2, y2) representing coordinates of a bounding box around the sign in the image. THESE COORDINATES ASSUME THE ORIGINAL IMAGE. THE PICKLED DATA CONTAINS RESIZED VERSIONS (32 by 32) OF THESE IMAGES
To train the model, I used a learning rate of 0.001, 100 epochs, although I could have used far less, and a batch size of 128. I chose to use the Adam optimizer because from the papers I’ve read adaptive optimizers appeared to have the best performance and were the least computationally expensive.
My final model results were:
- training set accuracy of 0.998
- validation set accuracy of 0.954
- test set accuracy of 0.939
f an iterative approach was chosen:
- What was the first architecture that was tried and why was it chosen?
- I first chose the basic LeNet architecture.
- What were some problems with the initial architecture?
- The initial training sets were achieving training accuracies of nearly 1.000 while the validation accuracy was only around 0.870. This indicated that the model wasn’t able to generalize what it learned in the training set to the validation set well.
- How was the architecture adjusted and why was it adjusted? Typical adjustments could include choosing a different model architecture, adding or taking away layers (pooling, dropout, convolution, etc), using an activation function or changing the activation function. One common justification for adjusting an architecture would be due to over fitting or under fitting. A high accuracy on the training set but low accuracy on the validation set indicates over fitting; a low accuracy on both sets indicates under fitting.
- I moved on to try adding layers of convolutions as well as in the fully connected classifier layer. I then moved on to try some inception modules. From there improved the training data set and added dropout because the training set was achieving very good accuracies whereas the validation set was still achieving relatively poor performance.
- Which parameters were tuned? How were they adjusted and why?
- I played with the learning rate a bit but decided to leave it at 0.001. I increased the number of epochs based on where I saw the optimizer begin to stall.
- What are some of the important design choices and why were they chosen? For example, why might a convolution layer work well with this problem? How might a dropout layer help with creating a successful model?
- I think the dropout layers helped because it allowed the model to have backup methods of classification which further allowed the model to generalize to the validation set.
Here is an exploratory visualization of the data set. It is a bar chart showing how the training samples are distributed.

Number of training examples = 34799 Number of testing examples = 12630 Number of validation examples = 4410 Image data shape = (32, 32, 3) From the histogram we can see there are 43 classses
One thing you’ll notice about the training data set is that some classes are over-represented as compared to others. With this observation I opted to generate additional data to ensure that the distribution was more even. To add more data to the the data set, I translated images, rotated them and applied an affine transformation to shear them.
My final training set had 146574 images (after modified images being added). My validation set and test set had 4410 and 12630 images. These last two numbers were unaltered because they were given to us as separate pickles. Interestingly when I used train_test_split to generate validation images instead of using the ones given to us I achieved higher validation rates, which makes me question the validation image set that was given to us.
Here are some examples of modified images that were added to the data set:

And here is the histogram of how many images there are after processing for each class:

Here is a random sampling of data from the set of non-processed and processed imagery fed to the network for training:

schikit learn was used to shuffle the data, and tensorflow was used as the primary machine learning library.
Model Architecture
from sklearn.utils import shuffle
import tensorflow as tf
from tensorflow.contrib.layers import flatten
def LeNet(x):
# Hyperparameters
mu = 0
sigma = 0.1
# SOLUTION: Layer 1: Convolutional. Input = 32x32x1. Output = 28x28x6.
conv1_W = tf.Variable(tf.truncated_normal(shape=(5, 5, 3, 6), mean = mu, stddev = sigma))
conv1_b = tf.Variable(tf.zeros(6))
conv1 = tf.nn.conv2d(x, conv1_W, strides=[1, 1, 1, 1], padding='VALID') + conv1_b
# SOLUTION: Activation.
conv1 = tf.nn.relu(conv1)
# SOLUTION: Pooling. Input = 28x28x6. Output = 14x14x6.
conv1 = tf.nn.max_pool(conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='VALID')
# SOLUTION: Layer 2: Convolutional. Output = 10x10x16.
conv2_W = tf.Variable(tf.truncated_normal(shape=(5, 5, 6, 16), mean = mu, stddev = sigma))
conv2_b = tf.Variable(tf.zeros(16))
conv2 = tf.nn.conv2d(conv1, conv2_W, strides=[1, 1, 1, 1], padding='VALID') + conv2_b
# SOLUTION: Activation.
conv2 = tf.nn.relu(conv2)
# SOLUTION: Pooling. Input = 10x10x16. Output = 5x5x16.
conv2 = tf.nn.max_pool(conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='VALID')
# SOLUTION: Flatten. Input = 5x5x16. Output = 400.
fc0 = flatten(conv2)
# SOLUTION: Layer 3: Fully Connected. Input = 400. Output = 120.
fc1_W = tf.Variable(tf.truncated_normal(shape=(400, 120), mean = mu, stddev = sigma))
fc1_b = tf.Variable(tf.zeros(120))
fc1 = tf.matmul(fc0, fc1_W) + fc1_b
# SOLUTION: Activation and dropout.
fc1 = tf.nn.relu(fc1)
fc1 = tf.nn.dropout(fc1, keep_prob)
# SOLUTION: Layer 4: Fully Connected. Input = 120. Output = 84.
fc2_W = tf.Variable(tf.truncated_normal(shape=(120, 84), mean = mu, stddev = sigma))
fc2_b = tf.Variable(tf.zeros(84))
fc2 = tf.matmul(fc1, fc2_W) + fc2_b
# SOLUTION: Activation and dropout
fc2 = tf.nn.relu(fc2)
fc2 = tf.nn.dropout(fc2, keep_prob)
# SOLUTION: Layer 5: Fully Connected. Input = 84. Output = 43.
fc3_W = tf.Variable(tf.truncated_normal(shape=(84, 43), mean = mu, stddev = sigma))
fc3_b = tf.Variable(tf.zeros(43))
logits = tf.matmul(fc2, fc3_W) + fc3_b
return logits
x = tf.placeholder(tf.float32, (None, 32, 32, 3))
y = tf.placeholder(tf.int32, (None))
keep_prob = tf.placeholder(tf.float32)
one_hot_y = tf.one_hot(y, 43)
rate = 0.001
EPOCHS = 100
BATCH_SIZE = 128
logits = LeNet(x)
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits, one_hot_y)
loss_operation = tf.reduce_mean(cross_entropy)
optimizer = tf.train.AdamOptimizer(learning_rate = rate)
training_operation = optimizer.minimize(loss_operation)
correct_prediction = tf.equal(tf.argmax(logits, 1), tf.argmax(one_hot_y, 1))
accuracy_operation = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
saver = tf.train.Saver()
def evaluate(X_data, y_data):
num_examples = len(X_data)
total_accuracy = 0
sess = tf.get_default_session()
for offset in range(0, num_examples, BATCH_SIZE):
batch_x, batch_y = X_data[offset:offset+BATCH_SIZE], y_data[offset:offset+BATCH_SIZE]
accuracy = sess.run(accuracy_operation, feed_dict={x: batch_x, y: batch_y, keep_prob: 1.0})
total_accuracy += (accuracy * len(batch_x))
return total_accuracy / num_examplesModel Training and Testing
# train
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
num_examples = len(X_train)
print("Training...")
print()
for i in range(EPOCHS):
X_train, y_train = shuffle(X_train, y_train)
for offset in range(0, num_examples, BATCH_SIZE):
end = offset + BATCH_SIZE
batch_x, batch_y = X_train[offset:end], y_train[offset:end]
sess.run(training_operation, feed_dict={x: batch_x, y: batch_y, keep_prob: 0.5})
training_accuracy = evaluate(X_train,y_train)
validation_accuracy = evaluate(X_validation, y_validation)
print("EPOCH {} ...".format(i+1))
print("Training Accuracy = {:.3f}".format(training_accuracy))
print("Validation Accuracy = {:.3f}".format(validation_accuracy))
print()
saver.save(sess, 'model')
print("Model saved")A validation set can be used to assess how well the model is performing, which I mentioned I used scikit learn to split up for me previously. The first ten epochs of training resulted in the following training and validation accuracies:
EPOCH 1 ... Training Accuracy = 0.678 Validation Accuracy = 0.617 EPOCH 2 ... Training Accuracy = 0.849 Validation Accuracy = 0.791 EPOCH 3 ... Training Accuracy = 0.913 Validation Accuracy = 0.867 EPOCH 4 ... Training Accuracy = 0.940 Validation Accuracy = 0.895 EPOCH 5 ... Training Accuracy = 0.957 Validation Accuracy = 0.905 EPOCH 6 ... Training Accuracy = 0.966 Validation Accuracy = 0.925 EPOCH 7 ... Training Accuracy = 0.974 Validation Accuracy = 0.927 EPOCH 8 ... Training Accuracy = 0.977 Validation Accuracy = 0.935 EPOCH 9 ... Training Accuracy = 0.981 Validation Accuracy = 0.935 EPOCH 10 ... Training Accuracy = 0.985 Validation Accuracy = 0.940
As we can see, the training and validation accuracies are still increasing, meaning beneficial learning is occurring. If we notice, however, that the validation accuracy begins to drop, it is evident that overfitting is occurring and the model is not able to generalize beyond its training data set.