
So, we’ve talked about least squares estimation and how we can weight that estimation based on our certainty in our measurements. Now let’s talk about when we want to do this shit online and roll in each subsequent measurement!
Things begin to get a bit more complicated now that we have an “update” step that requires us to fold in new information, but we are getting closer and closer to the more complicated Kalman filter. In order to fold in this newly acquired data, we add in a matrix, 
We will therefore amend our state equations as follows:

The difference this time being that we compute 


For the sake of expediency I’m going to skip most of the derivation of this one because the matrix equations continue to get longer, so let’s just jump right to the useful part of it all.
Recursive Least Squares Estimation Algorithm
We begin by first initiating the estimator as follows:
![\begin{aligned} 2) \displaystyle \qquad \hat{x}_0 &= E(x)\\ P_0 &= E \left [ (x - \hat{x}_0)(x - \hat{x}_0)^T \right ] \\ \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D++2%29+%5Cdisplaystyle+%5Cqquad+%5Chat%7Bx%7D_0+%26%3D+E%28x%29%5C%5C++P_0+%26%3D+E+%5Cleft+%5B+%28x+-+%5Chat%7Bx%7D_0%29%28x+-+%5Chat%7Bx%7D_0%29%5ET+%5Cright+%5D+%5C%5C++%5Cend%7Baligned%7D++&bg=ffffff&fg=000&s=1&c=20201002)
Where 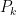


With the estimator initialized, let’s start chugging along. We update our estimate of x and the estimation-error covariance, P, with the following equations:

Where 
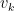
Here’s a picture I found from researchgate[1] that illustrates the effect of a recursive least squares estimator (black line) on measured data (blue line). This scenario shows a RLS estimator being used to smooth data from a cutting tool. Don’t worry about the red line, that’s a bayesian RLS estimator.

Slightly Sexier Examples (Curve Fitting)
Despite what many people with their resistor based examples of what least squares estimators will tell you, we can actually do some pretty cool things with these guys. Take for example curve fitting. Let’s suppose we are measuring the altitude of a free falling object. From basic physics we know that the underlying governing equation for this is a quadratic function of time:

Where r is position, 

In this scenario, our output equation takes the form
![\begin{aligned} 5) \displaystyle \qquad y_k &= x_1 + x_2 t_k + x_3 t_k^2 + v_k \\ E(v_k^2) &= R_k \\ H_k &= \left [ 1 \, t_k \, t_k^2 \right ] \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D++5%29+%5Cdisplaystyle+%5Cqquad+y_k+%26%3D+x_1+%2B+x_2+t_k+%2B+x_3+t_k%5E2+%2B+v_k+%5C%5C++E%28v_k%5E2%29+%26%3D+R_k+%5C%5C++H_k+%26%3D+%5Cleft+%5B+1+%5C%2C+t_k+%5C%2C+t_k%5E2+%5Cright+%5D++%5Cend%7Baligned%7D++&bg=ffffff&fg=000&s=1&c=20201002)
From here, it’s just a simple matter of initializing the estimator and then letting the algorithm governed by the equations set out in 3 do its thing, or what ever other flavor of least squares estimation you prefer.
In the words of Jerry Smith, later days, amigo.
Resources
- Mehta, Parikshit & Mears, Laine. (2014). Adaptive control for multistage machining process scenario—bar turning with varying material properties. International Journal of Advanced Manufacturing Technology. 10.1007/s00170-014-6739-x.